![Télécharge moi un PDF [QIMA]](https://welovedevs.com/wp-content/uploads/2020/06/qima2.jpg)
Hello ! Chez QIMA, on propose des services pour aider les marques à s’assurer de la bonne qualité des produits qu’on achète tous les jours.
Prenons un exemple ; Jean-Claude est acheteur pour une marque de prêt à porter et il passe commande de 15 000 paires de chaussures à une usine en Inde régulièrement. De temps en temps, il commande à QIMA une inspection de la production de l’usine de son fournisseur afin de vérifier que les normes ainsi que le cahier des charges sont bien respectés. Pour cela, il va spécifier le processus d’inspection à réaliser dans notre plateforme : les tailles, les mesures, les matières, les couleurs, la résistance souhaitée... puis un inspecteur QIMA à l’autre bout du monde va intervenir dans l’usine pour vérifier tout ça en suivant les instructions pas à pas. Une fois l’inspection complétée, un rapport est envoyé à Jean-Claude et en cas de problèmes, il peut par exemple décider de stopper la production et l’expédition de la commande afin d’éviter de retrouver des chaussures non conformes dans nos rayons !
Bref, j’avais envie de vous partager un des derniers défis qu’on a eu à relever dans ce contexte :
On avait déjà développé la page pour afficher le rapport de Jean-Claude dans l’application web et on avait besoin de lui permettre de télécharger ce rapport en PDF ou de le recevoir par email, comme s’il avait imprimé cette même page en PDF depuis son poste.
A priori, rien de bien fantaisiste ici. Ces technologies ont été inventées il y a plusieurs dizaines d’années, environs 30 ans pour le web et 26 ans pour le format PDF. #boring
Mais en creusant le sujet, plusieurs options s’offraient à nous et on s’est retrouvé à faire des choses inattendues et plutôt cool 😎
PDF generator: on save, publish a json event in pubsub that trigger a cloud function to run a static spa locally and use this json to display page with data then run chrome headless with puppeeter to generate PDF and publish it on a cloud storage bucket for future downloading 🤩 pic.twitter.com/7T2vamrAcw
— Cyril Lakech👨👧👩👧👦 (@cyril_lakech) May 8, 2020
WAT !? Je sais, ce n’est pas très digeste alors on va décomposer ce message :
“Quand un inspecteur qualité termine une inspection dans une usine, il l’indique dans l’application web mobile (PWA), ce qui va déclencher un évènement qui contient les résultats de l’inspection et qui va entrainer l’exécution d’un traitement sans serveur. [ndlr : sisi, il y a un bien un serveur même si c’est #serverless 😛]
Ce traitement consiste à démarrer un serveur web [ndlr : ah, tu vois !] qui publie dans une page web le rapport de l’inspection contenant ses résultats, puis à utiliser un navigateur web marionnettiste pour ‘imprimer’ cette page en PDF et enfin sauvegarder le fichier dans une solution de stockage dans les nuages.”
Euh… OK, par contre, est-ce que c’est possible de démarrer un serveur web dans une fonction serverless ? 🙃 Difficile de trouver cette réponse sur la toile.
Vous suivez toujours ? (ou pas) Entrons dans le détail !
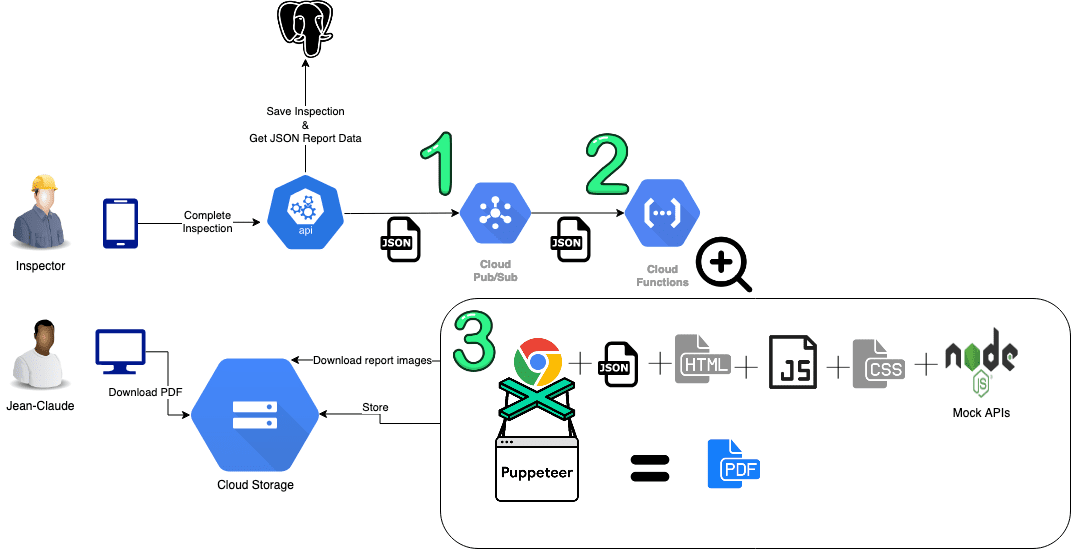 Ce schéma représente les différentes étapes entre l’inspection qui est complétée par l’inspecteur et le téléchargement du PDF par Jean-Claude.
Ce schéma représente les différentes étapes entre l’inspection qui est complétée par l’inspecteur et le téléchargement du PDF par Jean-Claude.
- Donc lorsque que l’inspecteur complète l’inspection, on créé un message qui contient toutes les informations nécessaires pour construire le rapport puis on ajoute ce message dans un système de messagerie afin de déclencher la création du PDF. Pour cela on utilise Google Cloud Pub/Sub mais je ne vais pas m’attarder sur ce point, car c’est bien documenté et dans de nombreux langages ici.
- Ce qui est pratique avec ce système de messagerie c’est qu’on peut l’utiliser pour déclencher un traitement pour chacun des messages reçus. Et ce traitement est réalisé grâce à une fonction nuagique, une Cloud Function. Cette partie est également bien documentée dans différents langages ici.
- Nous voici à la partie la plus
intéressantemonstrueuse, l’implémentation de la Cloud Fonction qui va créer le PDF et le stocker. Et là c’est plus coton pour trouver le code qui va bien sur stack overflow. En voici donc un exemple utilisant Node.js v10:
D’abord on récupère le fameux message JSON qui contient toutes les informations pour créer le rapport PDF :
const report = JSON.parse(Buffer.from(data, ‘base64’).toString());
Puis, on configure un serveur web avec express.js qui va publier l’application web ainsi que l’API dont la page d’affichage du rapport a besoin :
const app = express();
app.use(‘/api/inspections/:id/report’, (req, res) => res.json(report));
app.use(express.static(‘www’));
Le répertoire « www » est intégré au code de la fonction et il contient l’application web Angular de la plateforme, telle que vous pouvez la packager pour la déployer avec un serveur web classique comme nginx par exemple. Donc à la racine du répertoire www, on retrouve le fameux index.html et tous les assets web habituels.
Ensuite on trouve un port disponible sur l’environnement, on lance le serveur express sur ce port avant d’exécuter le marionnettiste puppeteer qui va ouvrir un navigateur chrome et naviguer sur l’url passée en paramètre pour enfin générer et stocker le PDF sur un bucket Cloud Storage. #ouf
const port = await portfinder.getPortPromise();
const server = app.listen(port, async () => {
const id = report.id;
const pdf = await render({ url: `http://localhost:${port}#/report/${id}` });
await storage.bucket(process.env.REPORT_BUCKET).file(`inspection/${id}/report.pdf`).save(pdf);
});
server.close();
On peut donc bien faire tourner un serveur dans un service serverless 😝 Ce qui se passe c’est que le navigateur contrôlé par puppeteer va afficher l’application web qui en se chargeant va faire l’appel d’API pour récupérer les données nécessaires à son affichage et comme les appels d’APIs, en JS, sont de la forme /api/inspections/** et bien c’est notre serveur express qui répond et retourne les données « mockées » du json reçu en paramètre. Dingue !
Ça c’était la version simplifiée et pas à pas, pour la version complète commentée, avec récupération des images du rapport sur des buckets GCP dédiées, c’est par ici et avec le petit package.json qui va bien https://gist.github.com/clakech/ec3dfabcac5cb3e321f4637d27e4d86d
Comme vous pouvez le voir dans le code, on utilise des dépendances comme le SDK NodeJS de Cloud Storage et également un wrapper de puppeteer qui aide à imprimer un PDF à partir d’une url https://github.com/alvarcarto/url-to-pdf-api Cependant, comme nous n’avons besoin que d’une petite partie de ce wrapper et comme il n‘est pas disponible sur npm, nous vous conseillons de reproduire votre propre configuration en vous inspirant du code dispo sur Github.
Voilà, une fois le pdf généré, il vous reste à développer l’UI et une API pour le télécharger. Rien de mystique ici.
Évidemment cet article est loin d’être complet, il manque des tests, le code n’est pas robuste et ne gère pas les erreurs et j’ai été au plus simple. Je vous ai passé les détails qui permettent à puppeteer de se connecter à l’application web via un cookie généré dans la fonction par exemple ou encore la partie infra as code pour automatise la création des pubsub/bucket/functions en terraform. C’est pour votre bien 😉
Si j’avais pu trouver cet article quand j’ai débuté ce chantier, ça m’aurais bien aidé, donc j’ai une pensée pour les prochains aventuriers du PDF.
On a plein d’autres défis à relever chez QIMA, sur le offline first pour notre application web mobile (PWA), l’intégration de l’UX/UI dans les process agiles, la mise en place de Cloud Run pour intégrer automatiquement les données de nos clients, le passage d’une API Spring Boot sur Quarkus… bref, à bientôt pour un nouveau billet de blog parce que WE <3 DEVS !!!
PS: On a une annonce en ligne à vous partager https://welovedevs.com/app/job/software-engineer-frontend-web-mobile-qima



