


MongoDB est une base NoSQL qui a pris le parti de faire fi de la séparation des données en différentes tables à réunir via des jointures. Dans mongoDB, les documents sont le plus souvent conçus pour héberger l’ensemble des données qui concernent cet objet, quitte à ce qu’il y ait de la duplication. Pour retrouver les fonctionnalités essentielles d’analyse de la donnée, MongoDB a créé le concept d’aggregation Mongo.
L’aggregation Mongo est une série d’opérations visant à prendre une collection de documents en entrée, procésser les documents et rendre une vision analytique de cette collection.
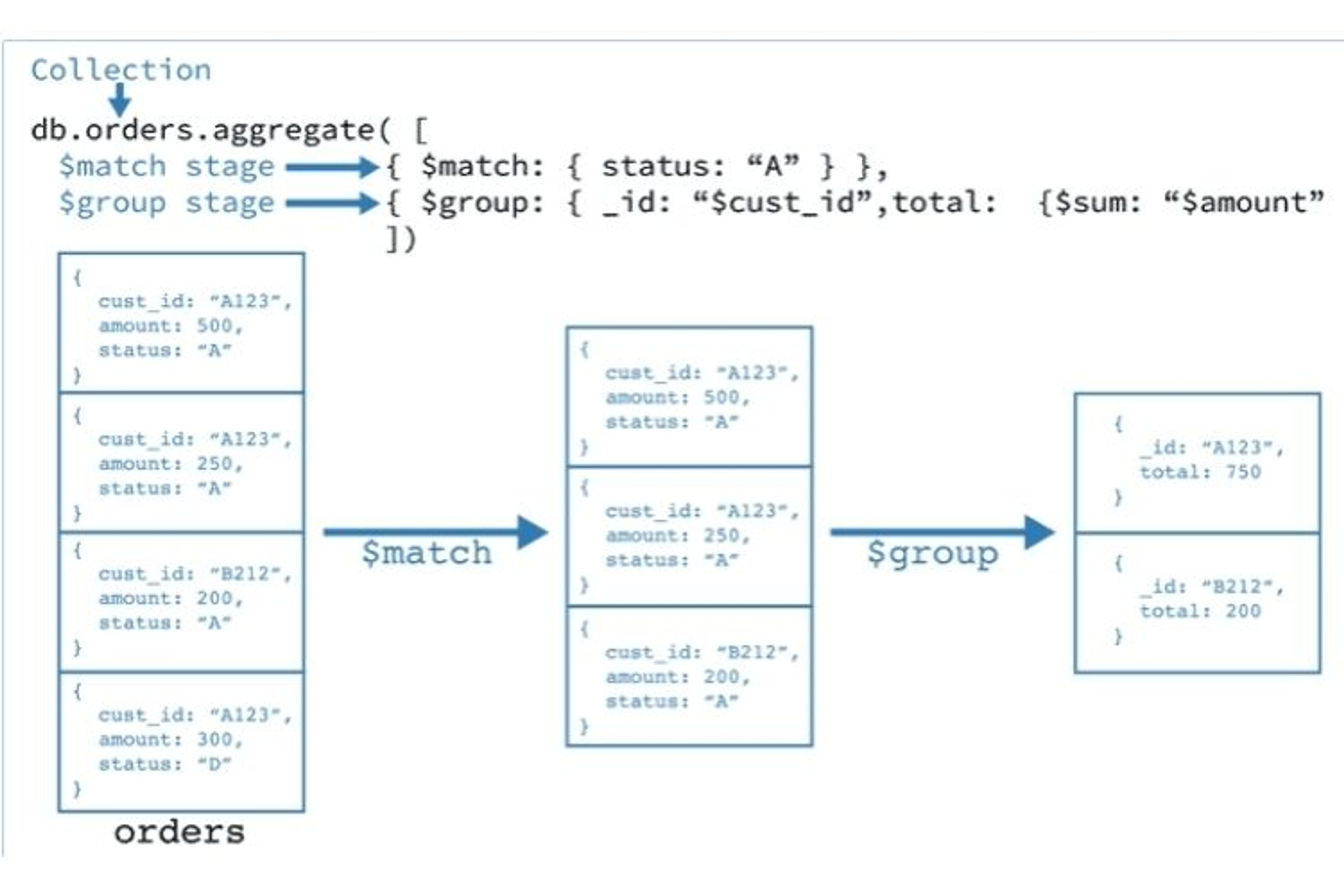
Les opérations d’aggregation mongo s’exécutent via la commande db.collection.aggregate(). Depuis la version 4.2 de mongo, vous pouvez également lancer des opérations d’aggregation mongo lors des commandes findAndModify et update
Pipeline d’aggregation mongo
Pour performer des opérations d’agrégation mongo, il faut définir une série d’opérations à travers lesquelles la collection va passer. L’output de chaque étape du pipeline sera l’input de l’opération suivante.
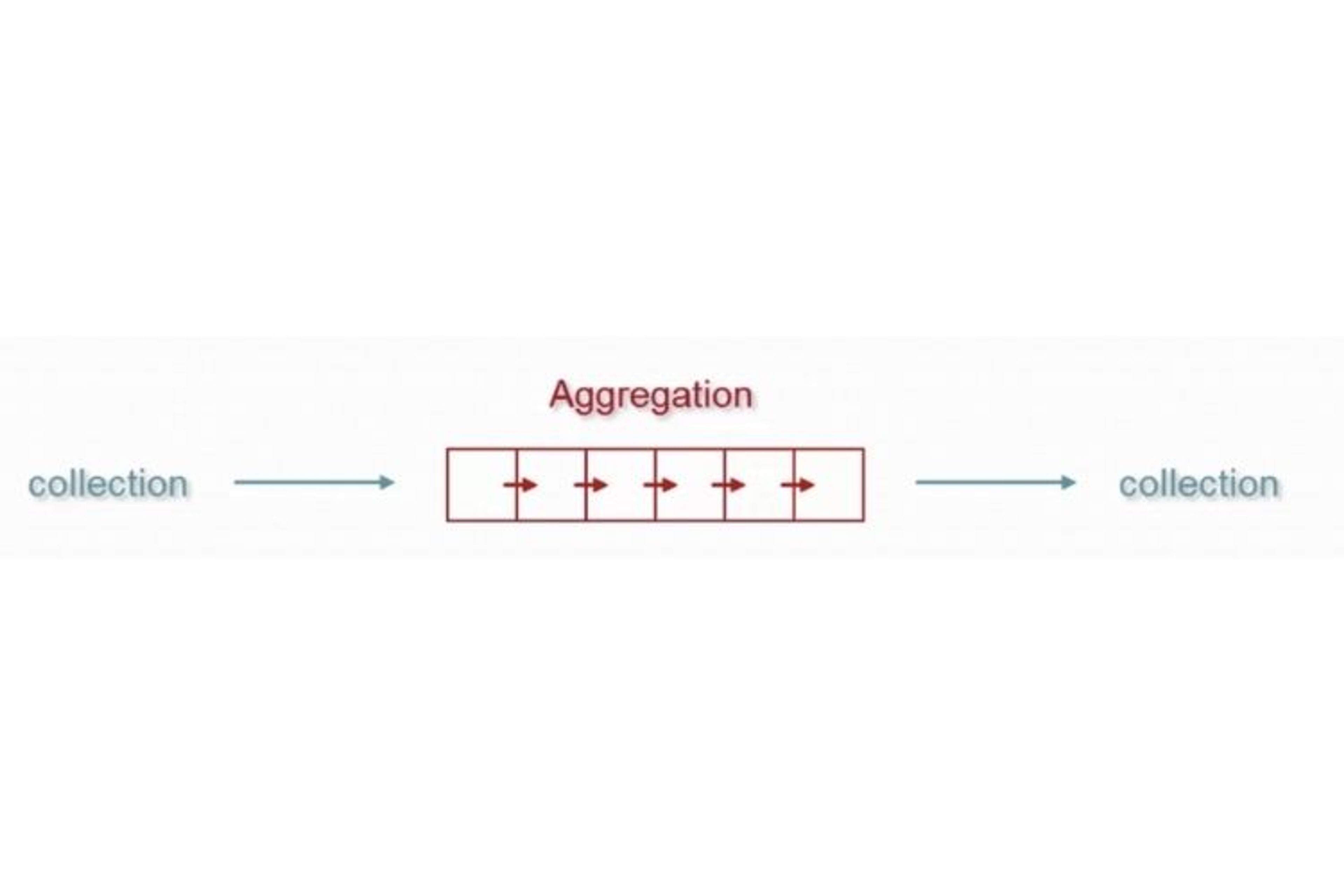
Les étapes du pipeline peuvent servir à exclure certains documents du pipeline ou à créer de nouveaux documents à la sortie. C’est pourquoi le nombre de documents à la sortie du pipeline ne sera pas forcément égal au nombre de documents à l’entrée.
Pour définir chaque étape du pipeline, on va passer les opérateurs dans la commande d’aggregation mongo :
db.collection.aggregate([operateurEtape1, operateurEtape2, operateurEtape3, ...])Les opérateurs d’agrégation mongo
$match
L’opérateur $match sert pour filtrer les documents d’une collection. Il est souvent le premier opérateur dans un pipeline d’aggregation mongo. Même si parfois, il arrive qu’en seconde position derrière l’opérateur $project, MongoDB sait identifier tous les champs présents dans le $match suivant et qui sont inexistants avant l’étape $project. Il effectue ensuite sous le capot un $match avant le $project, afin de limiter le nombre de documents à traiter.
Après l’étape du $match, il y a normalement moins de documents qu’avant cette étape.
$project
L’opérateur $project a pour but de remodeler chaque document dans la collection. Il prend en paramètre les spécifications que vous voulez mettre en place pour ce nouveau format de document attendu en sortie.
Par exemple si vous avez une collection « appartements » contenant des objets comme ceci:
{ _id : 1, type: "T2", squareMeters: 47, owner: { last: "Martin", first: "Laurie" }, city: "Paris" }Si vous appliquez l’aggregation mongo suivante:
db.appartements.aggregate([{ $project : { "type" : 1 , "squareMeters" : 1 }}])Vous obtiendrez l’objet suivant:
{ "_id" : 1, type: "T2", squareMeters: 47, }À la suite d’une opération $project, vous aurez autant de documents à la sortie qu’il y en avait à l’entrée.
$group
Comme son nom l’indique, l’opérateur d’aggregation mongo $group sert à regrouper les documents et faire des opérations d’accumulation sur les documents.
Par exemple, nous avons les objets suivants dans notre collection « appartements » :
[ { "_id" : 1, type: "T2", squareMeters: 47, city: "Paris" }, { "_id" : 2, type: "T3", squareMeters: 86, city: "Lille" }, { "_id" : 3, type: "T3", squareMeters: 84, city: "Lille" }, { "_id" : 4, type: "T2", squareMeters: 59, city: "Marseille" }, { "_id" : 5, type: "T4", squareMeters: 115, city: "Paris" }, { "_id" : 6, type: "T2", squareMeters: 39, city: "Paris" }]Si vous appliquez l’aggregation mongo suivante :
db.appartements.aggregate([{ $group : {_id : "$city",avgSize : {$avg : $squareMeters },count: { $count: $type}}}])La collection « appartements » vous affichera :
[ { "_id" : "Paris", avgSize: 67, count: 3 }, { "_id" : "Lille", avgSize: 85, count: 2 }, { "_id" : "Marseille", avgSize: 59, count: 1 }, ]L’opérateur $group vous retournera donc moins d’objets à la sortie qu’il n’en a reçu à l’entrée.
$unwind
L’opérateur $unwind est le seul opérateur qui va retourner plus de documents à la sortie qu’il n’en a pris à l’entrée. $unwind sert à aplatir les objets contenant un tableau en les dédoublants.
Si vous aviez une collection « articles » contenant le document suivant :
[ { _id : 1, name: "article 1", stock: [ {taille: 44, stock: 5}, {taille: 45, stock:4} ] } ]L’opérateur $unwind va dédoubler le document et vous retourner:
[ { _id : 1, name: "article 1" stock: {taille: 44, stock: 5}}, { _id : 1, name: "article 1" stock: {taille: 45, stock: 4}}, ]$lookup
L’opérateur $lookup est l’équivalent d’un LEFT OUTER JOIN en SQL. Disponible depuis la version 32 de mongo, c’est un véritable atout car jusque-là il n’était pas possible de faire ce type d’opérations.
$sort
Là aussi, son nom est suffisamment explicite. L’opérateur $sort a pour but de trier les documents en fonction d’une ou plusieurs propriétés de l’objet. Il peut les trier dans l’ordre croissant ou décroissant. Pour bénéficier des meilleures performances de MongoDB, il est fortement conseillé d’utiliser les index sort pour faciliter les requêtes de tri.
$sort arrive en fin de pipeline et ressortira le même nombre d’objets qu’il a reçu à l’entrée.
$limit et $skip
$limit retourne les N premiers documents du pipeline sans les modifier, où N est la limite spécifiée.
Pour aller plus loin
Il existe encore de nombreux opérateurs mongo dont vous pouvez vous servir pour vos aggregation mongo. Pour tirer tous les bénéfices de cette technologie de base de données, je vous invite à regarder la documentation MongoDB ainsi que nos articles sur le sujet :



