
Dans l’univers du Big Data et du Cloud, Snowflake a vu le jour en étant le premier fournisseur d’un Data Warehouse sur le cloud 100% scalable. Dans cet article, découvrez ce qu’est un Data Warehouse et en quoi Snowflake est une solution innovante pour les entreprises.
Snowflake est l’éditeur d’une solution d’infrastructure de données dans le cloud permettant de rassembler l’ensemble des données, produites par les différents systèmes d’information d’une entreprise, au sein d’une même source de vérité afin de s’en servir dans des buts d’analyses ou d’entraînement de modèles de machine learning.
Fondé en 2012, Snowflake a vu le jour à San Mateo en Californie grâce à trois Français, Benoît Dageville, Thierry Cruanes, et Marcin Zukowski, tous trois anciens salariés de la société Oracle.

Snowflake est le premier Data Warehouse sur le Cloud
Après deux ans de travail dans l’appartement de Thierry Cruanes à San Mateo à développer le produit, Snowflake voit le jour en Octobre 2014 et devient le premier service de Data Warehouse-as-a-Service, venant bousculer un marché vieillissant de solutions on-premise et prenant d’avance AWS, GCP et Azure le puisqu’à cette époque, aucun des géants du cloud n’a investi ce segment du cloud.
Quelles que soient leurs tailles, les entreprises ont compris que les données qu’elles génèrent peuvent cacher des informations permettant de mieux comprendre leurs clients ou exécuter leurs missions.
Le big data est un vaste écosystème avec de nombreuses technologies permettant d’exploiter plusieurs téraoctets de données. Il s’agit bien évidemment d’une opportunité exploitable par les grandes entreprises ou les scale-ups générant un volume significatif de données et disposant d’un budget conséquent pour exploiter cette opportunité.
Quand est-ce qu’une entreprise doit s’intéresser au BigData ?
Toute entreprise va créer des données pour faire fonctionner son activité. Cela commence par des listings de clients et de prospects, puis des devis et des factures, auxquels s’ajouteront les transactions, les échanges de mails, les interactions sur les différents médias sociaux.
Au fur et à mesure que l’entreprise grandit, les sources de données vont se multiplier et les formats vont être de plus en plus variés.
On va parler de Big Data lorsque le volume, la variété et la vélocité des données deviennent tellement grands que les logiciels traditionnels ne suffiront pas à répondre à cette masse de données.
En dessous d’un téraoctet de donnée, une base de données relationnelle type PostgreSQL ou une base de données MongoDB est suffisante pour répondre à la plupart des besoins d’une entreprise.
En revanche, si le volume de données augmente et que les besoins métiers pour plus d’analyses ou traitement de données se font sentir, il faudra envisager la séparation des bases de données nécessaires au bon fonctionnement du système d’information de l’entreprise des données nécessaires à de l’analyse.
Dans ce cas, il faudra envisager un Data Lake ou un Data Warehouse.
Entre besoins métier et besoins analytiques
Suivant l’activité de l’entreprise, les besoins d’exécution du métier peuvent imposer des contraintes techniques. Les différentes technologies de bases de données se répartissent en deux grandes familles suivant leurs missions principales.
Les bases de données ayant vocation à stocker des données en temps réel. C’est le cas des bases de données MySQL ou MongoDB. On les catégorise comme bases de données OLTP (Online transaction processing).
D’autres technologies ont l’analyse de données au cœur de leurs préoccupations. Il s’agit de bases de données OLAP (OnLine Analytical Processing). Elles sont capables de traiter d’importants volumes de données rapidement afin de produire différents rapports. Par exemple, imaginez une base de données qui va centraliser l’ensemble des ventes réalisées par chaque caisse de tous les supermarchés et hypermarchés Carrefour. Si vous souhaitez faire la somme, par jour, de tout le chiffre d’affaires réalisé grâce aux fruits et légumes, les technologies OLAP permettent de faire ce traitement 1000 fois plus rapidement qu’une technologie OLTP.
Snowflake, et les Data Warehouses en général, font partie de ces technologies OLAP. Elles ont pour vocation de permettre à différentes applications d’accéder et manipuler rapidement certaines données via des requêtes SQL, voir Python, R ou d’autres langages.
Data Lake ou Data Warehouse
Lorsqu’une organisation décide d’investir dans le big data, une des premières étapes est de définir une infrastructure pour collecter les données. Les deux principales formes de stockage de données big data sont les Data Lakes et les Data Warehouse.
Pour distinguer ces deux types de gisements de données, il faut comprendre l’utilité de chacun d’eux ainsi que leurs utilisateurs.
Le Data Lake, appelé aussi lac de données, est un lieu où les différentes applications du système d’information de l’entreprise vont déverser les données qu’elles peuvent collecter ou produire avec très peu de traitements en amont.
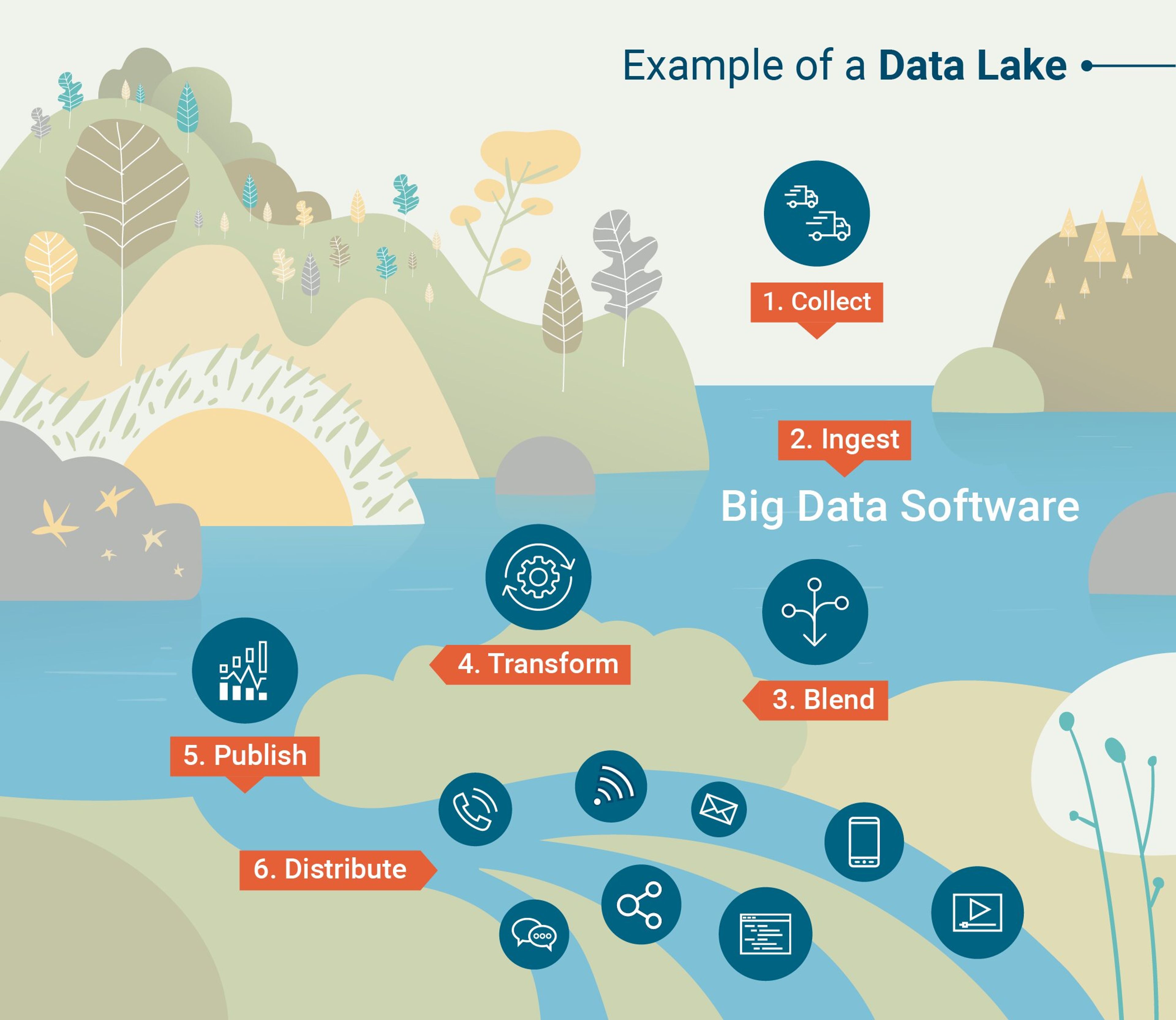
Un Data Lake est une base de données analytiques permettant de déverser des données avec très peu de traitements en amont
Les données présentes dans un Data Lake sont le plus souvent à plat, c’est-à-dire sans jointures ou références, provenant de sources diverses, et peuvent être structurées, semi-structurées ou non structurées.
Cette infrastructure est souvent la plus facile à mettre en place mais la plus difficile à exploiter. En effet, le format très volatil des données va nécessiter du traitement avant de pouvoir être exploité. Sans cette réflexion et ce travail de traitement, un Data Lake peut se transformer en Data Swamp, ou marécage de données, rendant les données qu’il contient inexploitables.
Le Data Warehouse, ou entrepôt de données, est un modèle d’infrastructure plus travaillé. Les données entrantes dans l’entrepôt nécessitent d’être traitées avant d’y être stockées. Le Data Warehouse base l’exploitation des données qu’il renferme sur un processus d’ETL (Extract, Tranform, Load) permettant de charger les données issues des différentes applications.
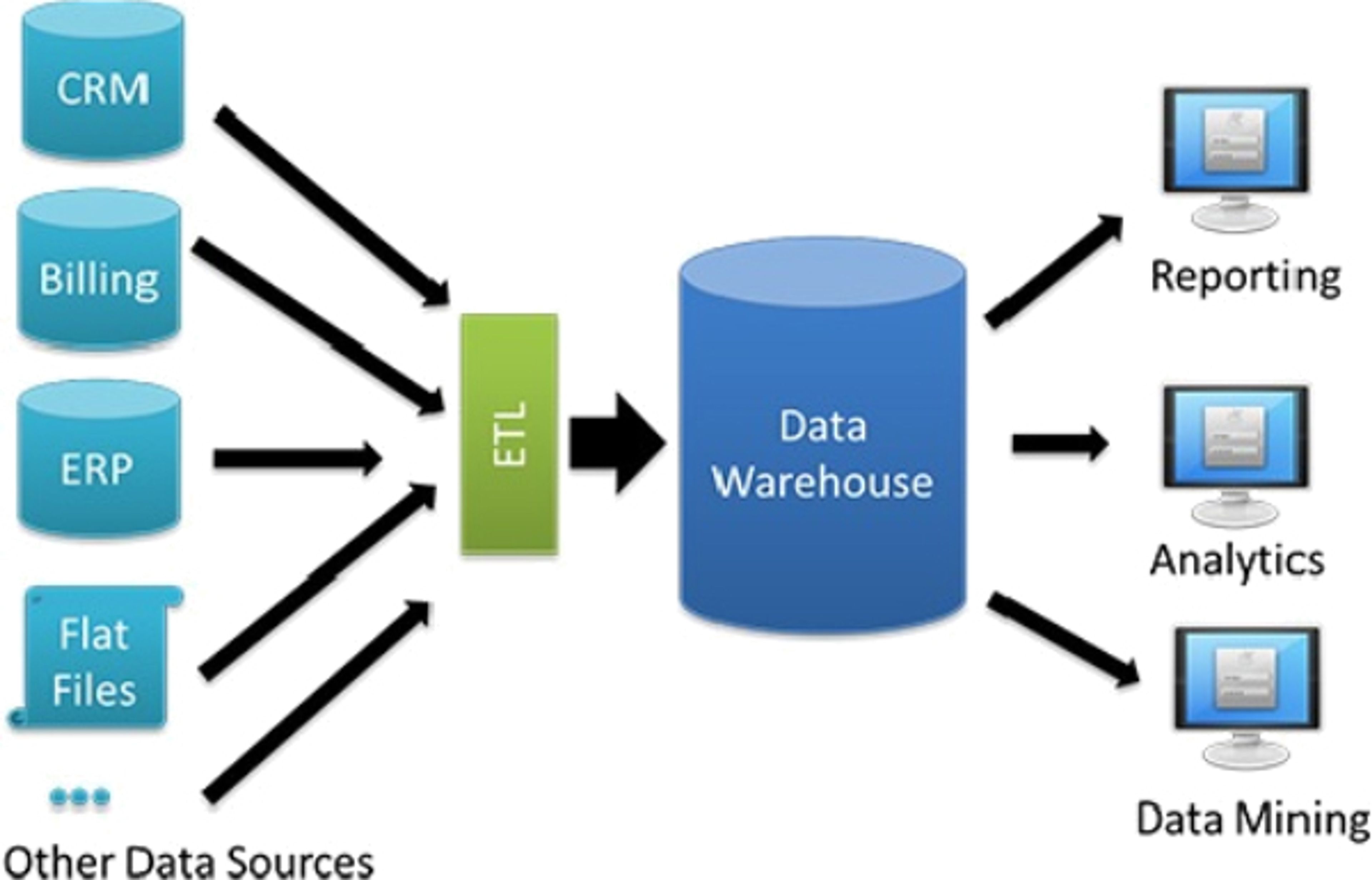
Un Data Warehouse va recueillir l’ensemble des données de l’entreprise après un traitement préalable par un ETL
Pour assurer le bon fonctionnement du Data Warehouse, les données collectées être:
- Orientées sur le sujet : les données sont organisées par thèmes, permettant de catégoriser l’intégralité des données de l’entreprise dans un même entrepôt
- Intégrées : les données doivent être traitées puis intégrés au data warehouse, quelle que soit leur provenance. Elles peuvent venir de bases de données traditionnelles OLTP, comme une base de données relationnelle utilisée dans une application du SI, ou de source externe comme des données analytiques ou en provenance de sources tierces comme Facebook ou tout autre réseau social.
- Comporter une variante temporelle : Les données stockées sont immuables. Contrairement à une base de données traditionnelle qui va venir modifier une ligne si besoin, les objets stockés dans un data warehouse vont rester immuables et chaque modification va venir ajouter une nouvelle ligne. Cela permet d’avoir un historique complet pour chaque objet.
- Non volatiles : Une fois stockées, les données ne pourront plus être effacées.
Snowflake : Qu’est-ce que c’est ?
À son lancement en octobre 2014, Snowflake était la première solution de Data Warehouse conçue pour être proposée sur un cloud. Le nom commercial choisi pour la solution était Snowflake Elastic Data Warehouse.
L’idée pour Snowflake Elastic Data Warehouse était de proposer aux utilisateurs une solution, dans le cloud, qui rassemblerait toutes les données et les processus de traitements dans un seul entrepôt de données, tout en garantissant de bonnes performances dans le traitement des données, de la flexibilité dans leur stockage et de la facilité d’utilisation pour les utilisateurs.
Snowflake a commencé par les propositions de valeurs suivantes:
- Data warehousing as a service. Grâce au Cloud, Snowflake élimine les problématiques d’administration d’infrastructure et de gestion de base de données. À l’instar des DBaaS, les utilisateurs peuvent se concentrer sur le traitement et le stockage des données. En s’affranchissant d’une infrastructure physique, le coût d’un entrepôt de données devient variable et peut s’adapter à la taille et à la puissance requise par le client.
- Une élasticité multidimensionnelle. Contrairement aux produits du marché à l’époque, Snowflake avait la capacité de monter en capacité en espace de stockage et en puissance de calcul de manière indépendante pour chaque utilisateur. Ainsi, il était possible de charger de la donnée tout en faisant tourner des requêtes sans avoir à sacrifier de la performance car les ressources sont dynamiquement allouées en fonction des besoins à chaque instant.
- Destination unique de stockage pour toutes les données. Snowflake permet de stocker de manière centralisée l’ensemble des données structurées et semi-structurées de l’entreprise. Les analystes souhaitant manipuler ces données pourront y accéder dans un seul système sans avoir besoin de traitement avant de pouvoir faire leur travail d’analyse.
L’architecture unique de Snowflake
Une architecture hybride entre le Shared Disk et le Share Nothing
Snowflake rend possible le stockage et l’analyse de données à grande échelle grâce à son architecture innovante. Étant exclusivement un produit cloud, Snowflake se base sur des instances de calculs virtuelles, comme Elastic Cloud Compute (EC2) chez AWS, pour les opérations de calculs et d’analyses, en complément d’un service de stockage, comme Simple Storage Service (S3), pour persister la donnée dans le Data Warehouse.
Comme pour toute base de données, un cluster Snowflake dispose de ressources de stockage (ou mémoire disque), de mémoire vive et de puissance de calcul CPU. Snowflake repose sur une architecture hybride, en mêlant du disque partagé (Shared-Disk Architecture) à une architecture isolée (Share Nothing Architecture).
L’ensemble des données stockées dans le Data Warehouse Snowflake est rassemblé dans un seul répertoire, à l’instar des architectures à disque partagé, et est accessible par tous les nœuds (ou nodes) de calculs présents dans le cluster.
En revanche, les requêtes faites sur Snowflake utilisant des clusters de calculs MPP (Massively Parallel Processing) sont traitées par des nœuds où chaque cluster ne contient qu’une portion des données présentes dans le Data Warehouse.
En mélangeant les deux approches, Snowflake propose la simplicité de la gestion de la donnée grâce à son espace centralisé de données, tout en alliant les performances d’une architecture Share Nothing pour les requêtes sur les données que le warehouse peut contenir.
Les trois couches de Snowflake
Le Data Warehouse Snowflake repose sur 3 couches:
- Le stockage de données
- Le traitement des requêtes
- Les services cloud
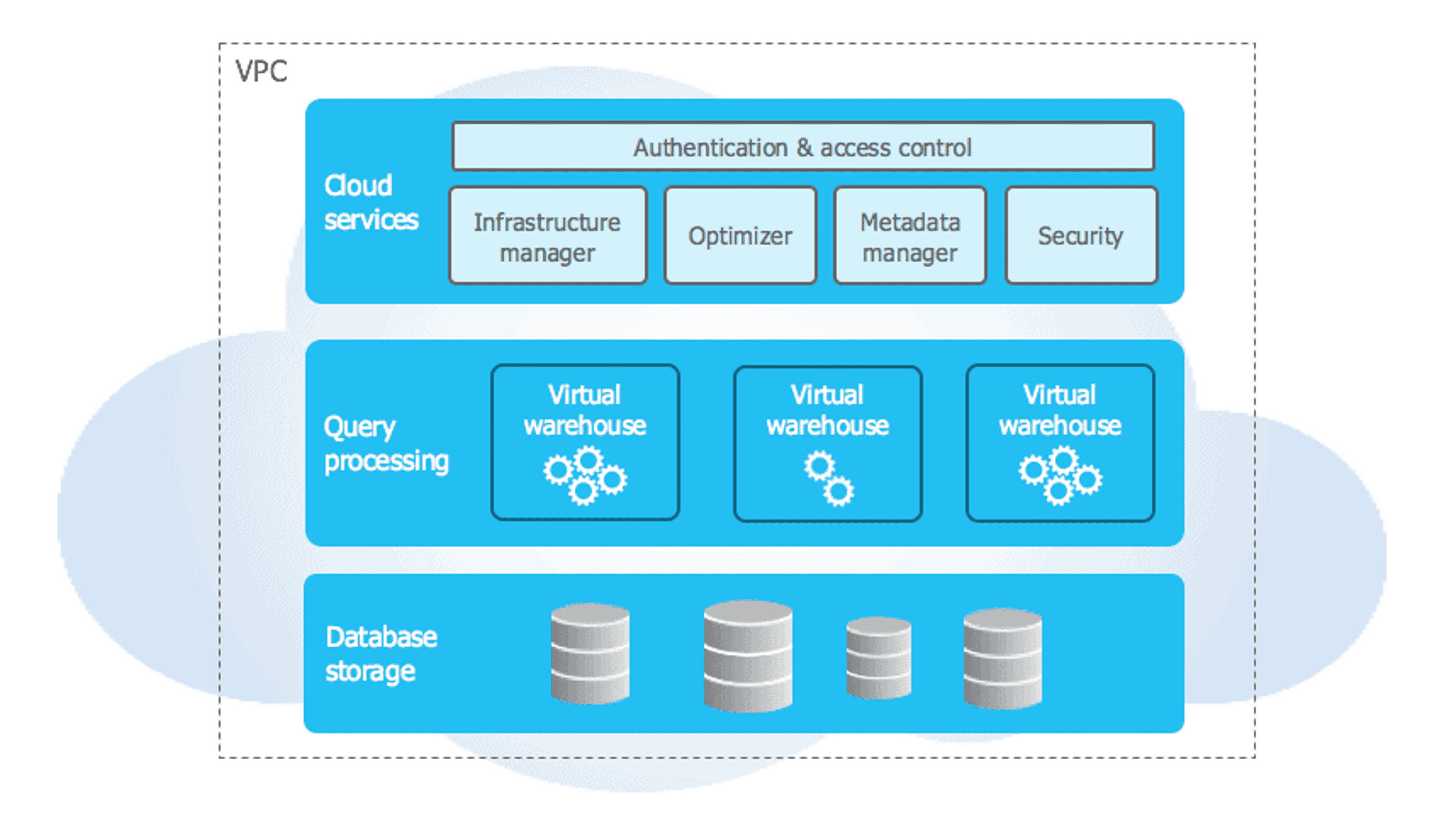
Snowflake distingue 3 couches à son Data Warehouse: Les services cloud, le traitement des requêtes et le stockage des données
Lorsque de la donnée est inséré dans votre Warehouse Snowflake, ce dernier la compresse, la réorganise dans son format de colonnes et l’enrichi de metadatas et statistiques. Les données brutes ne seront plus accessibles directement mais uniquement via les requêtes (SQL, R ou Python) faites à travers Snowflake.
Snowflake dispose également d’une couche de traitement pour traiter les requêtes sur les données. Les requêtes sur les données sont exécutées sur des « virtual warehouses », ou entrepôt de données virtuel. Chaque entrepôt virtuel est un cluster MPP qui repose sur une architecture Share Nothing, disposant de plusieurs nœuds, mais ne stockant qu’une partie de l’intégralité de la donnée du Data Warehouse.
Chaque Virtual Warehouse est capable de traiter une multitude de requêtes simultanées, et le cluster de calcul est capable de grossir ou de se réduire suivant la charge de travail à un instant T. Les différents entrepôts virtuels ne partagent aucune ressource, ni de calcul, ni de mémoire, ni de stockage, permettant à chaque entrepôt de ne pas avoir de conflit de ressources ou de requêtes en concurrence sur une même donnée.
Enfin, les services Cloud forment la couche supérieure de l’infrastructure Snowflake, permettant à différents services de se coordonner à travers l’infrastructure d’un Data Warehouse. Ces services permettent aux utilisateurs de s’authentifier, de lancer ou optimiser des requêtes sur les données, d’administrer les clusters et bien d’autres fonctionnalités.
La protection des données dans Snowflake
Snowflake s’assure de l’intégrité des données qu’il héberge via deux fonctionnalités, le Time-Travel et le Fail-Safe.
Le Time Travel permet, lorsque la donnée est modifiée, de garder son état pendant toute la durée configurée. Limité à une seule journée d’historique dans la version standard, le Time Travel peut être configuré jusqu’à 90 jours dans la licence Entreprise de Snowflake et permet de revenir à un état précédent d’une table, un schéma ou une base de données complète.
La fonctionnalité Fail Safe propose une sauvegarde de 7 jours après la fin de la période de Time Travel afin de récupérer de la donnée qui serait corrompu par des erreurs lors d’opérations.
Ces deux fonctionnalités sont elles-mêmes créatrices de données et contribuent à remplir l’espace de stockage facturé du cluster Snowflake.
Tarifs: Combien coûte un cluster Snowflake ?
Snowflake étant un produit disponible exclusivement sur le cloud, son prix varie en fonction de votre utilisation et est impacté par trois paramètres, sous-jacent au fonctionnement du service. Il s’agit des coûts de stockage, des coûts de calcul et du niveau de service souhaité.
Les coûts de stockages, très simples et explicite sur Snowflake, sont de $23 par mois, par tranche d’un téraoctet, si vous faites le choix de payer en avance une année d’utilisation. Si vous souhaitez payer mensuellement, il faudra gonfler le prix mensuel à $40 par téraoctet.
Les coûts de calculs sont plus complexes à appréhender puisque ceux-ci peuvent varier suivant le choix du fournisseur cloud (Azure, AWS ou GCP) ainsi que de la région géographique où vous souhaitez héberger votre cluster.
Snowflake va mesurer une unité de capacité de calcul en ce qu’ils appellent un credit. Ce credit représente une heure complète d’un nœud de calcul de taille XS. Snowflake va vous facturer à la seconde d’utilisation de votre warehouse, tout en gardant une facturation minimum d’une minute.
Suivant les critères de support, les fonctionnalités et les standards que vous souhaitez pour votre Warehouse, il faudra choisir une licence Snowflake. Pour un même credit, ce dernier aura un coût différent suivant la licence pour laquelle vous opterez.
Pour une PME qui souhaite se lancer dans le big data et qui met en place son premier Data Warehouse, le budget à prévoir pour un cluster Snowflake est d’environ 7 000€ par an avec un prépaiement.
Pour une société de plus grande envergure, ingérant beaucoup de données et nécessitant de grosses capacités de traitement et de calculs, les factures peuvent monter au-delà des 500 000€ annuels.
La page des tarifs Snowflake ne permet pas de faire une simulation des coûts d’un cluster mais il existe des calculateurs non-officiels pour vous aider à estimer vos coûts annuels pour un Data Warehouse Snowflake.
Avantages d’utiliser Snowflake
Aujourd’hui, plus de 6000 entreprises ont fait le choix de Snowflake, payant collectivement plus d’un milliard de dollars à la firme américaine.
- L’architecture hybride de Snowflake est son véritable atout, donnant aux utilisateurs la capacité de lancer de la manière la plus efficace possible et simultanément des requêtes complexes sur un large volume de donnée
- Snowflake propose aussi une disponibilité multi-cloud et multi-région. Que votre SI repose sur AWS, GCP ou Azure, Snowflake pourra s’y conformer
- L’adaptabilité sur des données structurées (ordonnées en colonnes façon SQL) et semi-structurées (XML, JSON, Avro, Parquet…) est un autre point fort de Snowflake. Celui-ci est capable d’ingérer ce type de données et de les réadapter en interne de façon à répondre aux futures requêtes impliquant ce type de données.
- L’accessibilité aux données pensée par Snowflake permet aux administrateurs d’ouvrir des accès en lecture seule directement depuis leur interface cloud Snowflake. Ces applications ou partenaires externes à l’entreprise pourront s’appuyer sur le volume de données et les performances de traitement avec des droits limités sur l’accès aux données du Warehouse.
Pousser des données vers Snowflake
Le défi d’un Data Warehouse est de pouvoir y pousser des données, à la fois produites en interne par les différentes applications du système d’information de l’entreprise, que des données externes pouvant être utiles à des travaux d’analyses.
Pour effectuer ce chargement de données vers un Data Warehouse tel que Snowflake, il est essentiel de passer à travers un ETL. Celui-ci est un logiciel permettant d’Extraire, de Transformer puis de charger (Load), la donnée depuis son origine vers l’entrepôt en respectant les règles de formatage imposées par les schémas de données.
Utiliser des connecteurs pour les outils de marchés
Pour les applications de marché, telles que Salesforce, Shopify, SAP, Workday et bien d’autres, utilisées par les entreprises pour leurs fonctionnements, il existe une multitude de connecteurs pour brancher directement l’application à Snowflake.
Stitch et Fortran sont deux exemples de services ETL (Extract, Transform, Load) proposant un catalogue de connecteurs, allant d’applications métier à même des bases de données cloud ou on-premise.
Snowflake pour le Machine Learning
Les projets de Business Intelligence sont les premiers consommateurs d’un Data Warehouse comme Snowflake.
Mais depuis la démocratisation du Machine Learning et du développement de produits tels que TensorFlow, ou d’API de ML prêtes à l’emploi, les fournisseurs de Data Warehouse voient une nouvelle typologie de clients se connecter à leur source de données.
Snowflake a mis à la disposition des Data Scientists des connecteurs vers des produits de Machine Learning tels qu’AWS SageMaker ou Dataiku.
Quelles sont les alternatives à Snowflake
Bien que Snowflake ait été le premier acteur à se définir comme fournisseur d’un Data Warehouse sur le cloud, plusieurs produits provenant des fournisseurs Cloud eux-mêmes ont vu le jour pour le concurrencer.
Amazon Redshift
Redshift est le produit de Data Warehouse proposé par Amazon Web Services. À l’instar de Snowflake, Redshift est conçu pour être rapide et scalable.
Cependant, il est basé uniquement sur une architecture Share Nothing, contrairement à Snowflake qui s’appuie sur du Shared Disk et du Share Nothing

Amazon Redshift est le produit de Data Warehouse Cloud d’AWS
En termes de prix, Redshift associe stockage et puissance de calcul mais permet également aux utilisateurs de scaler la puissance de calcul uniquement.
Les clients optent pour un package Stockage & Puissance de calcul qui correspond à leurs besoins et peuvent dépasser ce forfait en payant un supplément à l’utilisation si un besoin ponctuel se fait sentir.
Redshift est notablement moins onéreux que Snowflake et propose même des réductions significatives en cas d’engagement et prépaiement sur un an ou sur trois ans.
Google Big Query
Big Query est l’offre de Data Warehouse proposée par Google Cloud Platform.

Google Big Query est l’équivalent Snowflake chez GCP
À l’instar des Google Cloud Functions, Big Query repose sur une architecture Serverless afin que ses utilisateurs n’aient pas à se soucier de la puissance de calcul ou l’espace de stockage de leur cluster. Celle-ci s’adaptera automatiquement aux requêtes et aux données qui lui seront envoyées.
Oracle Autonomous Data Warehouse
L’offre Oracle Autonomous Data Warehouse, tout comme Google Big Query, se veut être totalement automatisé, du déploiement à la sécurisation des données en passant par la connexion aux créateurs de données et la montée en charge si besoin.

Contrairement à Snowflake et aux concurrents cités ci-dessus, OADW est le seul à être disponible On-Premise pour les clients souhaitant continuer à exploiter une infrastructure de ce type.
Comment se positionne Snowflake sur le marché du Data Warehouse ?
Bien que précurseur du Data Warehouse dans le Cloud, Snowflake n’en est pas plus le leader pour autant.
D’après l’étude menée par enlyft, SAP Business Warehouse, une solution On Premise est leader avec près de 35% de parts de marché.
Ensuite arrive les acteurs Cloud, menés par Redshift. La solution proposée par AWS est attractive par son prix affiché attractif et ses intégrations faciles à tout l’écosystème AWS.
Snowflake arrive après RedShift avec 14% de parts de marché, devant Google Big Query qui n’en retient que 12%.
Comment les entreprises utilisent Snowflake ?
Tout l’intérêt de Snowflake, et d’un projet de Data Warehouse en général, est de pouvoir exploiter les données pour produire des conclusions sur le business, formuler des hypothèses et permettre à l’entreprise d’agir dessus.
Dans cette vidéo de présentation de Snowflake, nous explorons les données de Citi Bike, un service de vélo à la demande à New York, afin de comprendre certains phénomènes sur l’utilisation des vélos:

Snowflake aide Deliveroo à proposer plus de choix à ses clients
Si vous ne les connaissez pas déjà, Deliveroo est une startup britannique permettant aux consommateurs de se faire livrer à domicile des plats de leurs restaurants préférés. Soumis à une concurrence extrêmement rude avec Uber Eats, Deliveroo ont fait le choix d’utiliser Snowflake afin de prendre des décisions stratégiques pour faire face à cette concurrence.
En 2017, Deliveroo souhaitait augmenter le choix disponible pour ses clients en mettant à disposition aux restaurateurs des cuisines afin de préparer des repas au plus près des clients. Pour que l’investissement soit rentable, à la fois pour le restaurateur que pour Deliveroo, il fallait pouvoir identifier les zones où la demande était forte pour un certain type de plat en livraison et où l’offre de restaurants actuelle était insuffisante.
Grâce à Snowflake, Deliveroo a pu se baser sur des données internes pour savoir quels plats étaient déjà disponibles dans une zone donnée. Ils ont également pu capitaliser sur des données externes qu’ils ont déversées dans leur Data Warehouse, pour avoir plus d’informations sur la démographie et le trafic routier d’une même zone.
Deliveroo, qui utilisait précédemment un Data Warehouse Redshift d’AWS, a chargé son entrepôt de données Snowflake avec plus de 35Go de données en moins de 3 mois. Cette migration vers Snowflake a été menée pour répondre à un besoin croissant de requêtes simultanées et à des pics de charges de la part d’analystes et de différentes applications de Business Intelligence.
Hubspot
Hubspot est un éditeur SaaS qui met à disposition de ses clients un CRM pour aider ces derniers à faire croître leurs business en leur permettant d’attirer des prospects via du contenu promotionnel.
Avant d’utiliser Snowflake, les requêtes d’analyses se faisaient sur les mêmes machines que le déversement des données, ce qui provoquait des conflits d’accès à la ressource.
Leurs besoins d’analyses étant très variables, la puissance de calcul nécessaire n’était pas forcément linéairement utilisée. Avec leurs systèmes de base de données traditionnelle, Hubspot ne pouvait pas réduire la taille de son cluster sans avoir à faire plusieurs actions manuelles et se retrouvait à payer un cluster bien plus gros que ses besoins seulement en prévision d’un cas occasionnel où ils auraient effectivement besoin de toute la puissance de calcul disponible.

Hubspot a été séduit par Snowflake parce qu’ils peuvent maintenant avoir une puissance de calcul adaptative, qui va pouvoir monter en charge si les besoins se font sentir, et qu’il ne faudra pas payer si elle n’est pas utilisée.



