


Chez Alice’s Garden, le métier pilote l’activité commerciale via un vieil outil développé en interne il y a plusieurs années. Cet outil n’est plus maintenu par l’équipe interne de développement. (Il attaque directement la base de données en lecture via des requêtes SQL)
Ce logiciel permettait aux équipes de suivre l’évolution du chiffre d’affaires, des marges, du nombre de commandes et du panier moyen sur la période fiscale en cours. (une répartition par canaux de vente est aussi visualisable)
Des filtres de dates ainsi que des comparaisons sur les années précédentes sont disponibles.
Problématique: Le volume de données augmente de plus en plus d’années en années. Notre dashboard est vieillissant et met de plus en plus de temps à répondre (requêtes SQL de plus en plus longues). Cela devient une “contrainte de devoir travailler avec ça”, le logiciel doit continuer d’exister mais en tant que bouée de secours et non pour un usage quotidien.
Nous ne nous sommes pas trop posé la question de savoir si on allait développer quelque chose d’alternatif au précédent outil.
La data visualisation est un métier à part entière et développer une application de ce genre n’allait apporter aucune plus value à la société. De plus, les demandes en termes de statistiques étant très variées et non définies, cela aurait été très compliqué de le gérer en interne tout en sachant que des solutions Saas existent déjà et qu’elles fonctionnent très bien.
Quelle est la stack chez Alice’s Garden et de quoi est chargée l’équipe de développement ?
Alice’s Garden est un site de vente en ligne de mobilier de jardin (diversification en cours sur d’autres gamme d’ameublement).
Nous avons en interne 3 projets principaux et ainsi que d’autres secondaire:
- Une grosse API monolithique en PHP 7.3 (migration PHP 8 en cours) et Symfony 4.4 (migration vers Symfony 5.4 début 2022) qui nous sert à gérer toutes la SI de nos commandes / produits / site internet / flux avec des prestataires.
Techniquement, nous utilisons des technologies comme Rabbitmq / Elasticsearch / Varnish / Redis / API Platform.
- Un back office javascript (Angular JS + Angular 5) utilisé uniquement en interne pour piloter l’évolution des commandes pour la livraison client, le pricing et contenu de nos produits et la cosmétique de nos sites. Nous n’avons aucune intelligence métier, toute l’information est traitée par l’API.
- Un site internet en PHP 7.3 (migration PHP 8 en cours) et Symfony 4.4 (migration vers Symfony 5.4 début 2022) qui n’est juste qu’un outil de présentation de nos données de manière publique. Encore une fois, nous n’avons aucune intelligence métier, toute l’information est traitée par l’API excepté la gestion du panier.
Dans les projets secondaires, on peut trouver un outil de monitoring exécuté dans une lambda Amazon ou encore un projet d’anonymisation de base de données.
Choix des outils et mise en place de l’architecture
Outil de data visualisation et de stockage de données.

Chez Alice’s Garden, le métier avait déjà expérimenté la solution Qlik Sense. Cette dernière est capable de répondre à nos besoins, c’est pourquoi nous avons choisi cet outil. Par contre, afin de ne pas avoir tous nos oeufs dans le même panier, nous n’avons pas fait le choix de stocker nos données chez Qlik et de passer par une solution de data lake intermédiaire.
Concernant le data lake, nous avons choisi de nous orienter vers la solution Google BigQuery car celle-ci répondait bien en termes de gestion des coûts à notre manière de fonctionner.
On fait le point sur nos données et sur ce que l’on va injecter
Dans un premier temps, nous avons voulu reproduire les KPIs déjà disponibles dans notre dashboard actuel (CA / Marge / Panier moyen / Répartition places de marchés) ainsi que de pouvoir effectuer des filtres sur des dates / entrepôts / pays / groupe de pays et de pouvoir faire des comparaisons N-1 / S-1.
– Product (contenu produits avec référence unique pour tous les pays)
– ProductMarketplace (déclinaison de mon produit sur la place de marché avec son prix)
– Order (info de la commande)
– Ligne de commandes (info de la ligne de commande (ma commande est composée de plusieurs lignes de commandes))
– Stocks (les stocks produits)
– Arrivages (la liste des produits en cours d’import (quantité + date d’arrivage)).
Alimentation de BigQuery
BiqQuery supporte l’utilisation de SQL pour interagir avec ses données, ce qui nous allait bien dans un premier temps, vu que nous utilisons déjà Mysql dans nos projets actuels.
Architecture dans le code
Lorsque nous manipulons des chaînes comme des clefs, nous avons pour habitude de créer des constantes dans une classe qui leur est propre (exemple: nous avons une classe Table qui recense dans des constantes le nom de chaque table BigQuery).
Chaque table BigQuery est traduite en une classe de modèle PHP dans notre API (une propriété public pour chaque colonne).

Tous les modèles implémentent une interface qui impose la déclaration des méthodes suivantes:
<span style="font-weight: 400;">// Retourne la propriété que nous utiliserons comme clef (on gère l’update).</span>
<span style="font-weight: 400;">// Si un modèle n’a pas de clef, la donnée sera historisée (mode insert tout le temps)</span>
<span style="font-weight: 400;">public function getIdentifier(): ?string</span>
<span style="font-weight: 400;">// Retourne le nom de la table dans BigQuery</span>
<span style="font-weight: 400;">public function getTable(): string</span>
<span style="font-weight: 400;">// Retourne l’objet métier (cela peut réprésenter une entité doctrine, tout comme une autre source de donnée) concerné pour l’instanciation du modèle.</span>
<span style="font-weight: 400;">public function getBusinessObject(): string</span>
Tous les modèles sont injectés dans une classe de collection via l’injection de dépendances.
La classe de collection de modèles est capable de retourner le bon modèle pour un BusinessObject.

Pour la récupération de la donnée afin d’hydrater nos modèles BigQuery, nous avons des classes Populator qui sont toutes injectées dans une collection tout comme les modèles.
Dès que l’on a trouvé notre modèle, nous cherchons un populator qui pourrait l’hydrater, si aucun ne correspond à notre business object (via l’appel d’une méthode support()), celui de doctrine est utilisé par défaut.
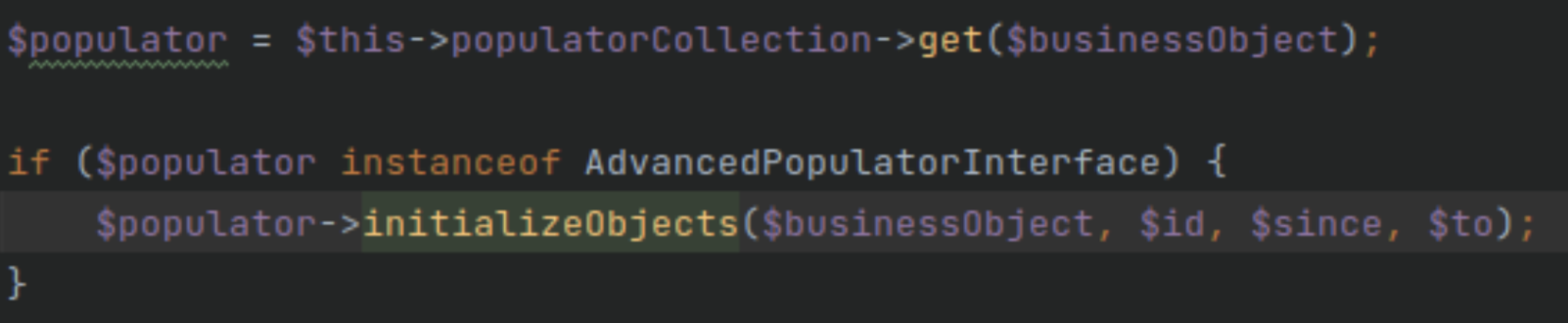
Test d’indexation, réalisation d’une commande
Afin de pouvoir tester rapidement notre indexation de données dans BigQuery, nous avons fait le choix de développer une commande Symfony (dans tous les cas, elle pourra servir si on a besoin de relancer des indexations complètes de nos données en cas de changement de schéma).
Insert / Update
Comme expliqué précédemment, nous avons deux typologies de modèles (une typologie où l’on va gérer une mise à jour de notre donnée et une autre où l’on va systématiquement insérer la data dans l’objectif d’avoir un historique des changements).
Le plus simple est le cas où l’on ne va faire que de l’insert, en effet une fois nos modèles instanciés grâce à notre populator, nous prenons notre tableau de modèles et on fait des paquets d’insert à insérer dans BigQuery.
Dans le cas d’un update, c’est un peu plus compliqué, une fois les modèles instanciés, nous allons chercher quels sont ceux qui sont déjà présents dans BigQuery. Si cela existe déjà, nous exécutons un update sinon cela rentrera dans un paquet d’insert.
Industrialisation (Premier essai) – Mise à jour en temps réel
L’idéal pour nous aurait été de pouvoir mettre à jour en temps réel notre BigQuery afin de tout le temps avoir de la donnée fraîche comme nous pouvons déjà le faire avec notre Elasticsearch.
Nous nous lançons alors dans le développement de subscribers qui écoutent les modifications de nos objets métier et qui déclenchent un appel (insert / update) à BigQuery.
Des criticals dans notre monitoring (Exceeded rate limits)
Nous sommes vite tombés dans des limites de quotas qui limitent le taux et le volume des requêtes entrantes.
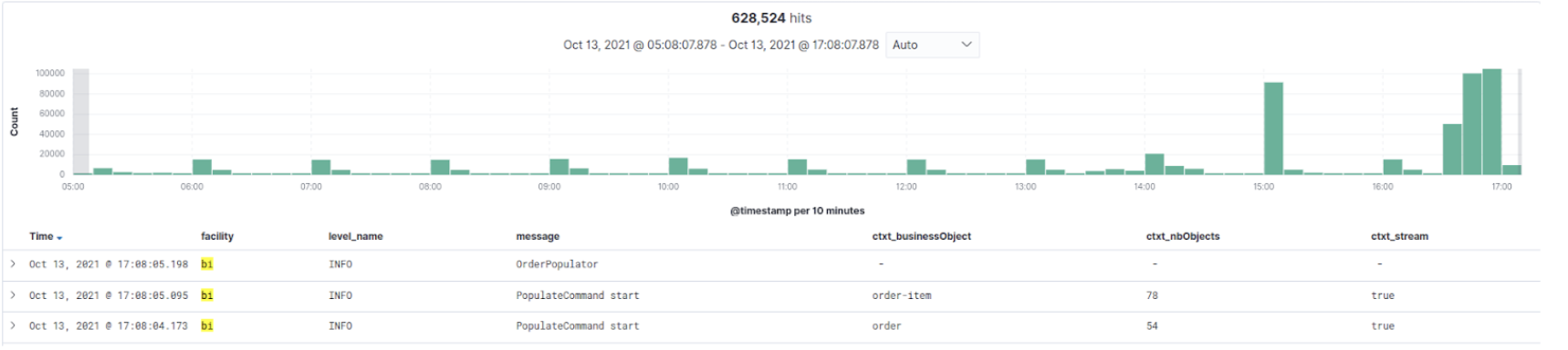
Exemple de notre écran Kibana
Industrialisation (Deuxième essai) – Mise à jour asynchrone
Nous nous sommes donc rabattu sur notre commande afin de la mettre en tâche CRON en y ajoutant des options de filtres afin de pouvoir récupérer un nombre restreint de données.
Pour plus de contrôle, nous avons ajouter un traitement asynchrone. La commande va se charger de récupérer la data et instancier les modèles qu’elle mettra dans des paquets qui seront envoyés à rabbitmq. Le consumer rabbitmq va se charger de construire les requêtes SQL grâce à la normalisation du modèle via le composant Serializer de Symfony et l’enverra à BigQuery à travers le client PHP de Google.
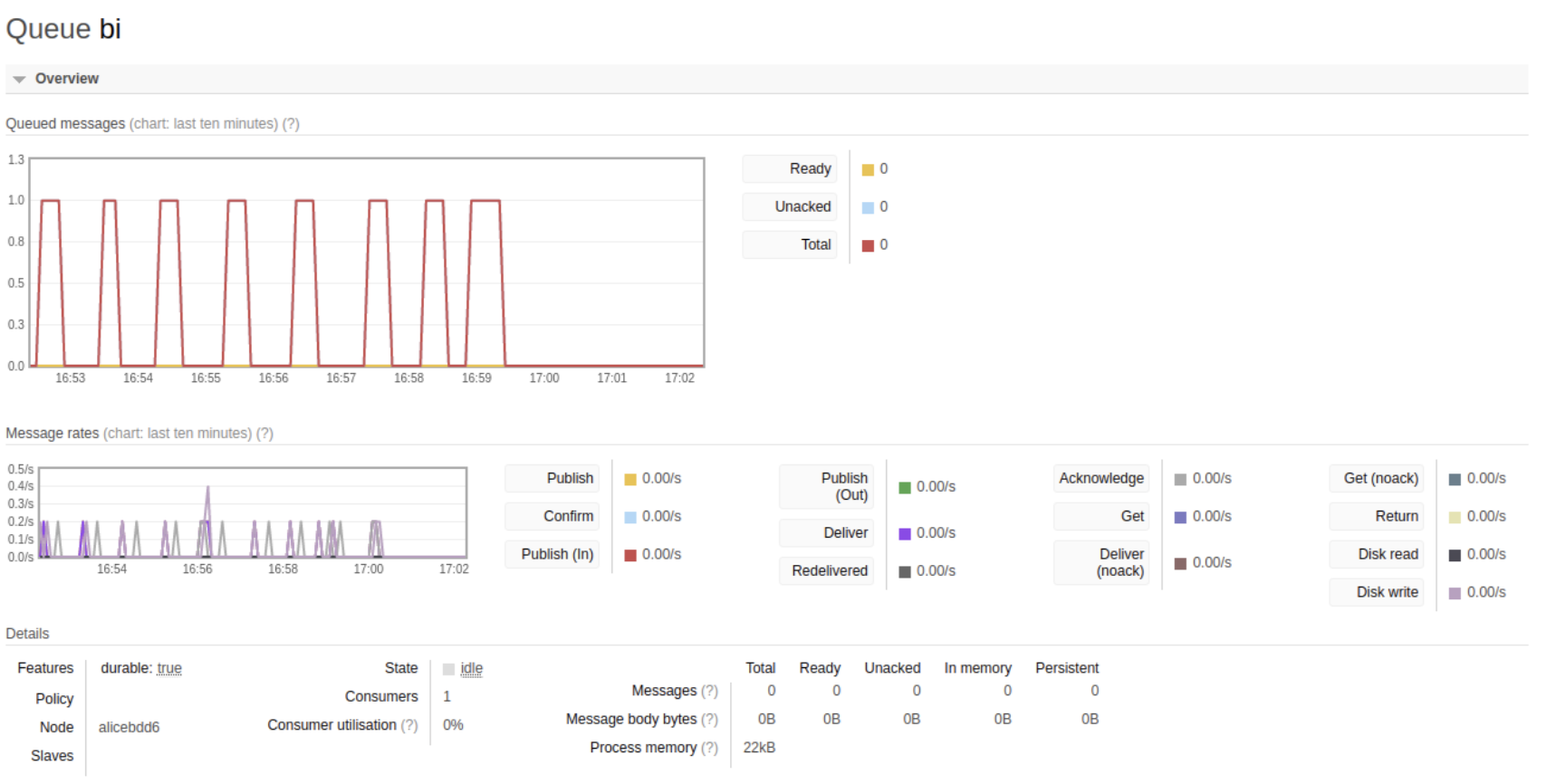
Des criticals dans notre monitoring (Exceeded rate limits)
On retombe dans les travers des quotas. On remarque via notre Kibana que les problèmes surgissent après des lots de requêtes d’update. En effet, le problème de l’update est que l’on peut pas travailler en mode batch comme avec de l’insert, chaque update concerne un seul enregistrement.
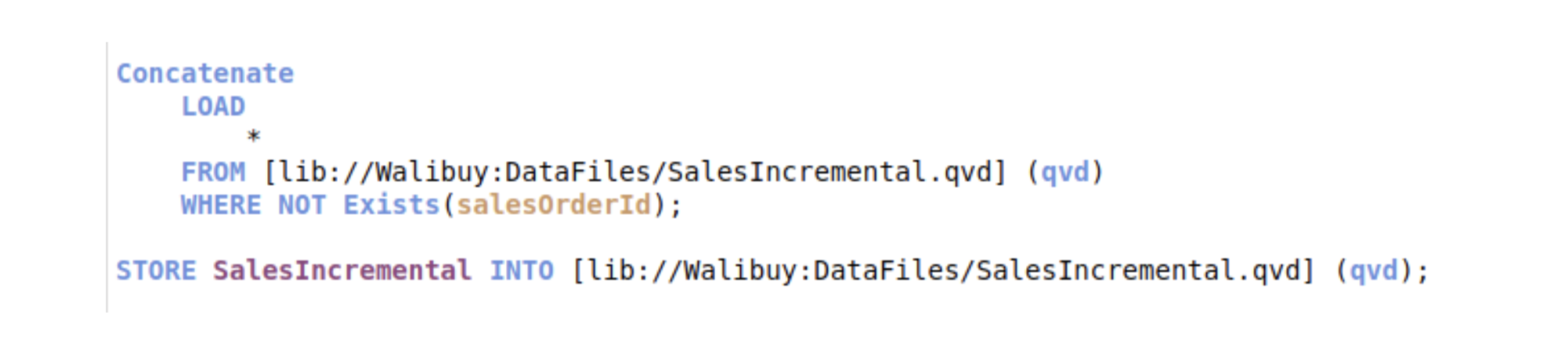
Le choix a donc été fait de tout gérer via de l’insert. A chaque fois que l’on ira chercher les objets déjà indexé dans BigQuery, nous ne chercherons plus à faire de l’update, mais on supprimera les lignes qui seront ré-inséré juste après.
Première étape de stabilité atteinte!
On rentre dans l’utilisation de Qlik
Modélisation d’un modèle de données pour une Business Intelligence
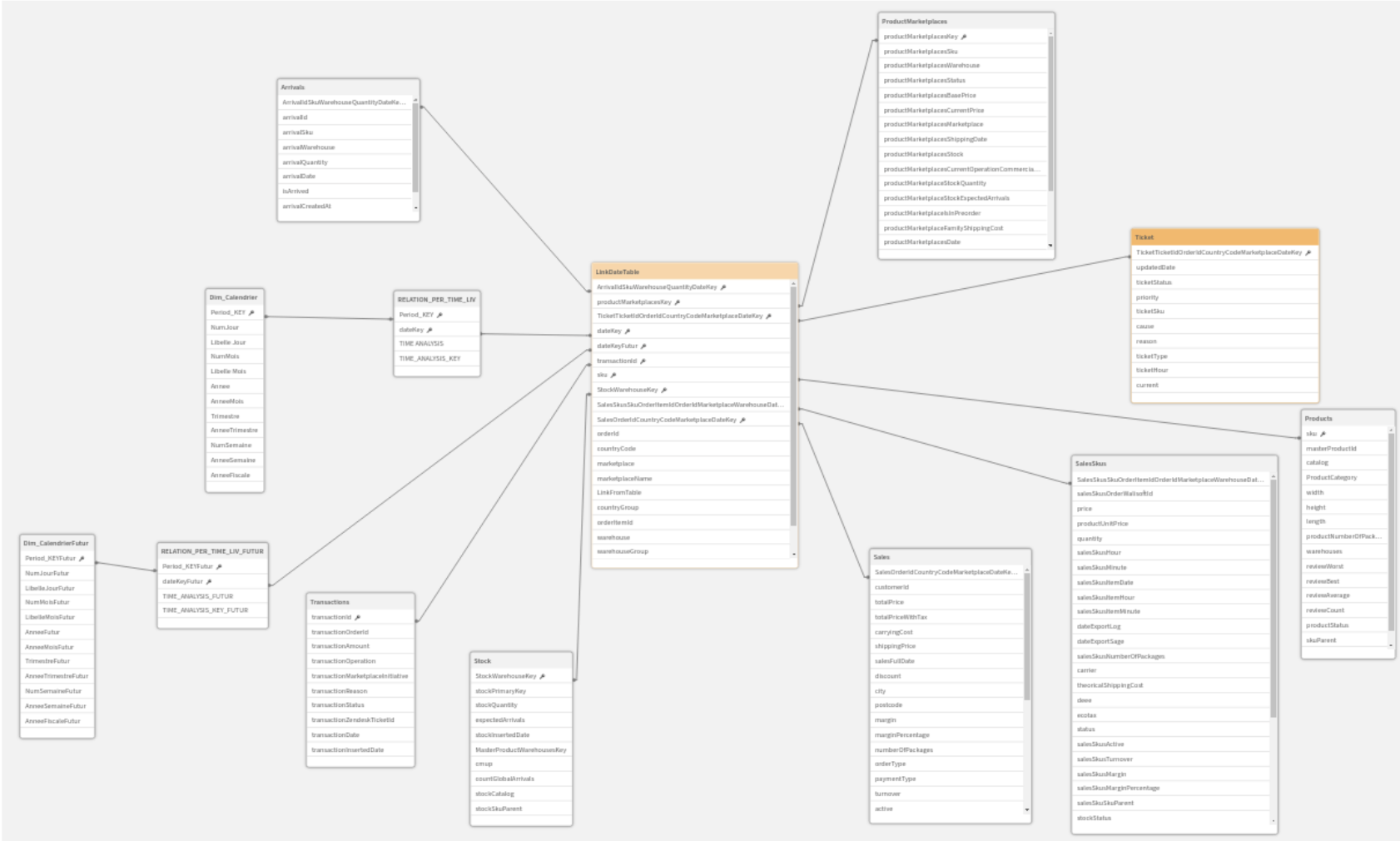
Dans une modélisation de données de Business Intelligence, l’objectif est de pouvoir croiser les données entre elles afin d’en sortir des statistiques. Deux techniques pour cela : tout mettre dans une seule et même table ou un schéma en étoile où l’on aura au centre notre table de mesure et tout autour nos dimensions pour effectuer nos filtres.
Au vu de la typologie très différentes de nos données (Produits / Stock / Prix / Commande / Ticket client…), il ne nous semblait pas très judicieux de tout mettre dans une seule et même table.
Ingestion des données dans Qlik
Modélisation
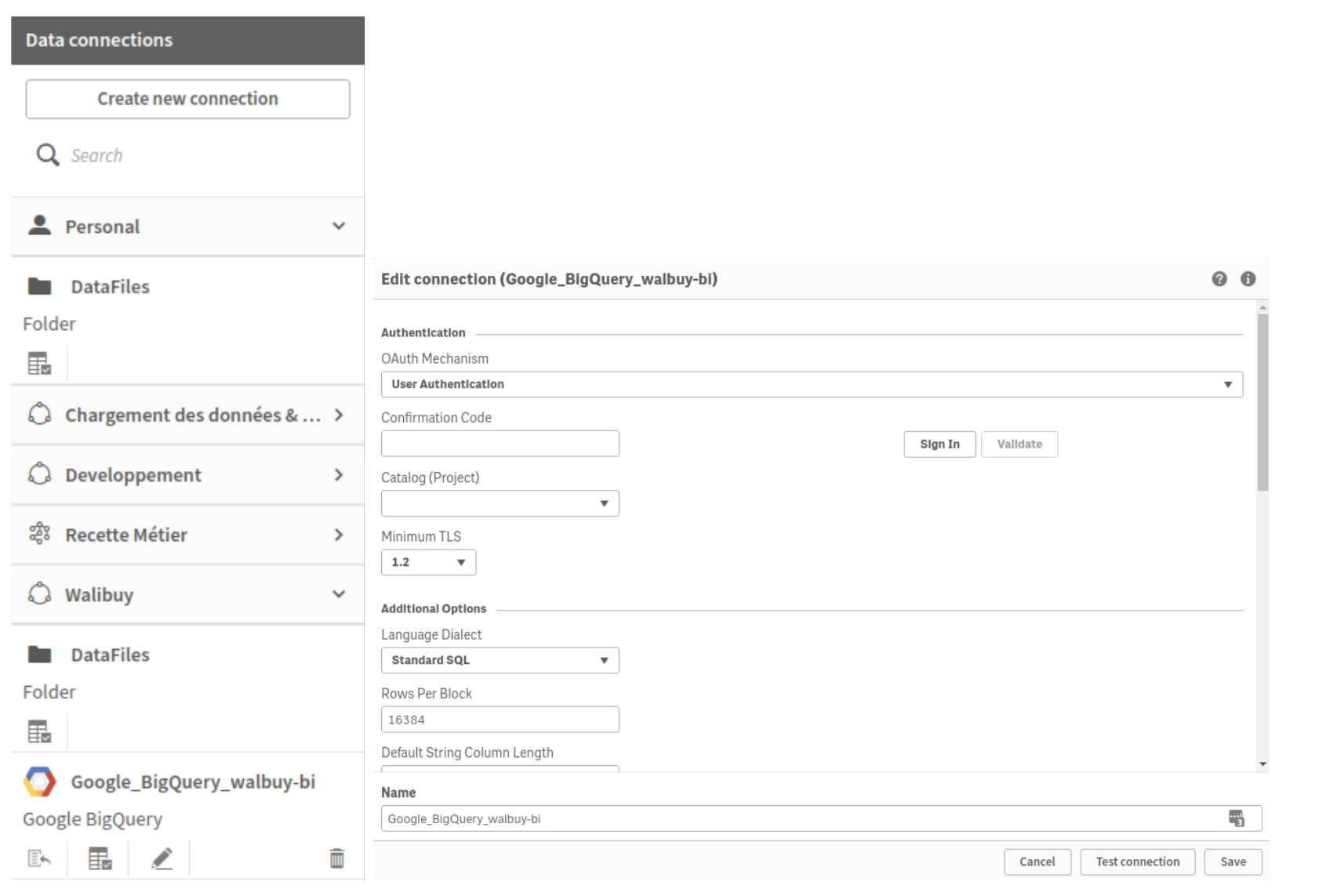
Dans Qlik beaucoup de sources de données sont disponibles (drive google / fichiers locaux / bucket Amazon S3 / BigQuery…). Il suffit donc de créer des connecteurs de données qui pourront être utilisés dans les scripts afin d’établir des connexions à nos sources de données et faire du requêtage.
Ensuite on peut travailler directement via l’IHM pour faire des SELECT * automatiquement ou scripter notre modèle nous même.
Nous n’allons pas rentrer dans le détail technique de la rédaction de script dans Qlik.
Gestion de la date
La gestion des dates n’est pas trivial non plus pour les comparaisons. Effectivement, ce qui est intéressant dans un outil de business intelligence lorsque l’on pilote du chiffre d’affaires est de comparer à des dates équivalentes mais plus précisément à des jours équivalents.
En effet, si je prends le 15 octobre 2021 qui est un vendredi, si je veux comparer avec l’année dernière, je ne dois pas prendre le 15 octobre 2020 car ce n’était pas le même jour et mes clients n’ont pas le même comportement selon le jour. Nous devons donc prendre le vendredi de la même semaine de l’année 2020. Pour cela, nous nous sommes servi des numéros de jour.
L’update de l’outil de Business Intelligence est de plus en plus long (15min pour tout charger)
Process de mise à jour de Qlik

Deux tâches CRON sont responsables de la mise à jour des données sur la BI.
- Une première qui lance le rechargement de Qlik et de lancer ses scripts d’import. Ces derniers se connectent à BigQuery pour récupérer l’ensemble des données. Cela prend à peu près 15 min et c’est déclenché toutes les 15min (Si on relance un chargement des données alors que le précédent n’est pas fini, le nouveau rechargement n’est pas pris en compte)
- Une deuxième qui est en fait en lot de tâches CRON configurées différemment selon l’objet métier qui est envoyé (Exemple, nous envoyons plus régulièrement l’état des commandes que l’état des stocks des produits).
Nous sommes donc encore loin du temps réel car nous avons de la latence entre la mise à jour de BigQuery et la mise à jour de Qlik.
Exemple:
11h25 Synchronisation des commandes dans BigQuery (~10min).
11h30 Nouvelle commande.
11h35 Début de chargement de données pour Qlik.
11h50 Fin du rechargement Qlik (si tout s’est bien passé), la commande de 11h30 n’est toujours pas là, il faudra attendre le futur rechargement (il sera donc à peu près 12h30 lorsqu’elle remontera).
Très dur à entendre pour le métier car l’outil actuel renvoie de la donnée en temps réel (même si c’est long, c’est mieux du coup).
Optimisations BigQuery
Rapatriement des données en Europe
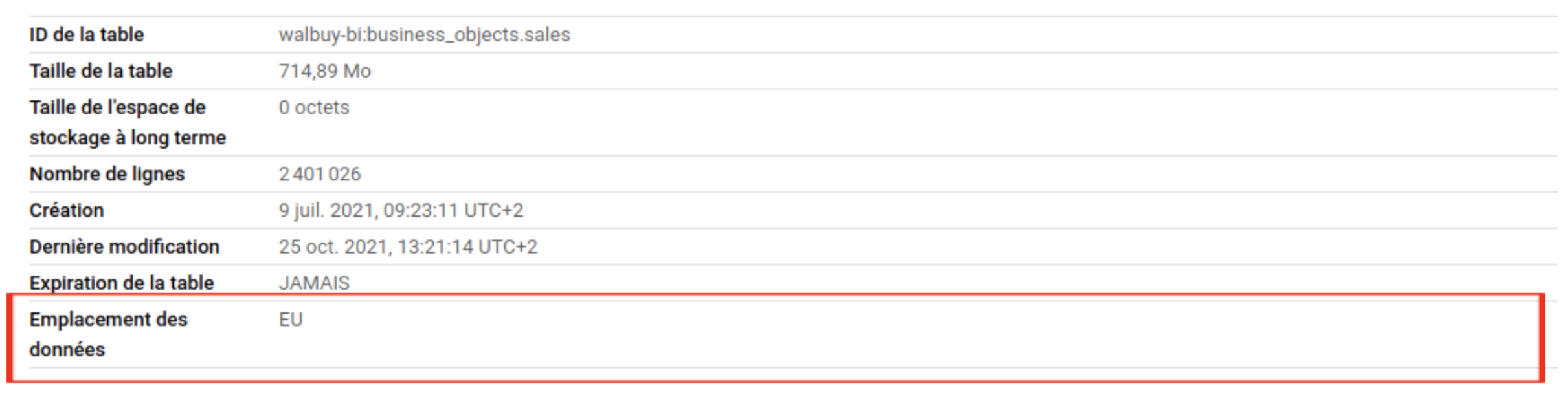
Par défaut, lorsque vous créez des tables dans BigQuery, celles-ci sont hébergées aux Etat-unis ce qui crée de la latence réseau lors du requêtage depuis nos serveurs qui se trouvent en Europe. Qlik étant aussi en Europe, cela pénalise de la même manière cette partie applicative. Pas de soucis concernant la RGPD, nous ne stockons pas d’information client dans notre BI (aucun nom / adresse (mis à part le code postal et la ville) / email / numéro de téléphone…).
Le changement de l’emplacement des données a donc consisté à créer une nouvelle table (en copiant le schéma) en précisant l’emplacement “Union Européenne”, copier les données de l’ancienne table vers la nouvelle, supprimer l’ancienne, renommer la nouvelle comme l’ancienne l’était etrefaire une synchronisation entre notre API et BQ.
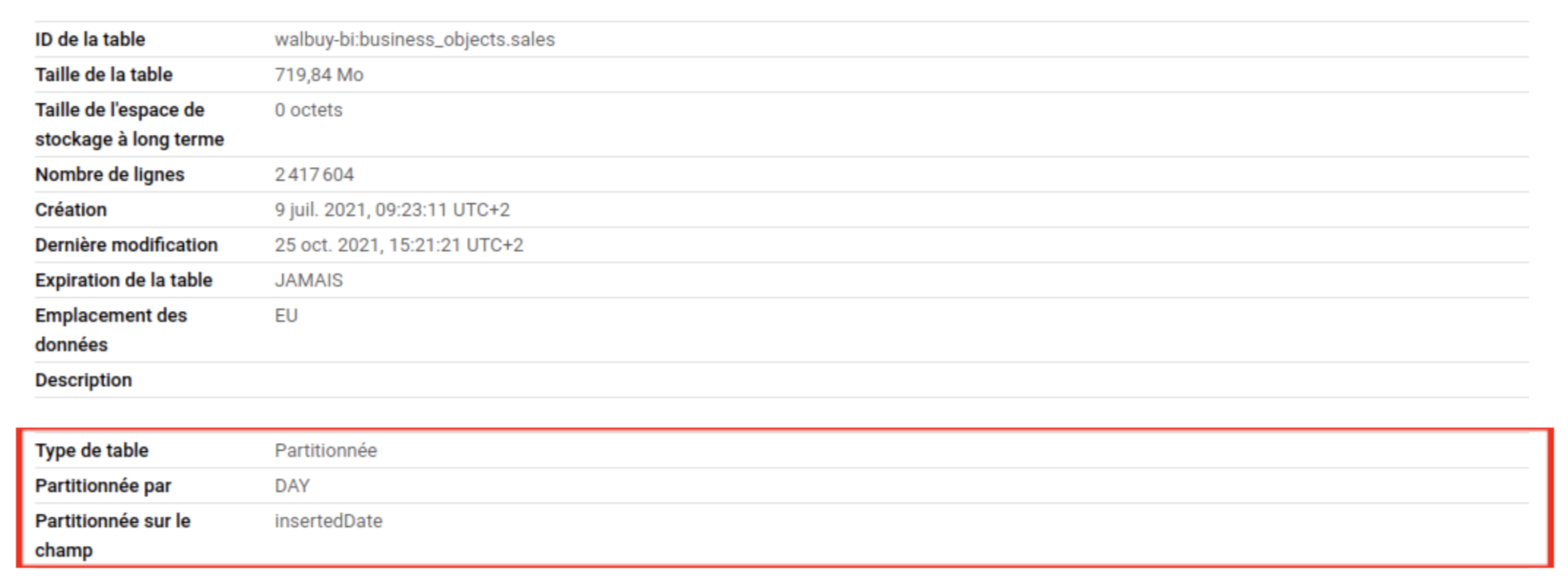
Mise en place du partitionnement
Sur BigQuery, le temps de traitement d’une requête dépend du nombre de données qui sont traitées par le moteur de requêtage (cela influe aussi sur le prix).
Si je fais une requête bornée sur des dates, je vais quand même traiter l’ensemble de données pour les filtrer. Pour réduire ce temps de traitement, il faut mettre en place du partitionnement sur la table afin que lorsque je filtre sur ma date, je ne traite que ce qui se trouve entre mes bornes.
En divisant une grande table en partitions plus petites, vous pouvez améliorer les performances des requêtes et maîtriser les coûts en réduisant le nombre d'octets lus par une requête.
https://cloud.google.com/bigquery/docs/partitioned-tables
Clustering de tables
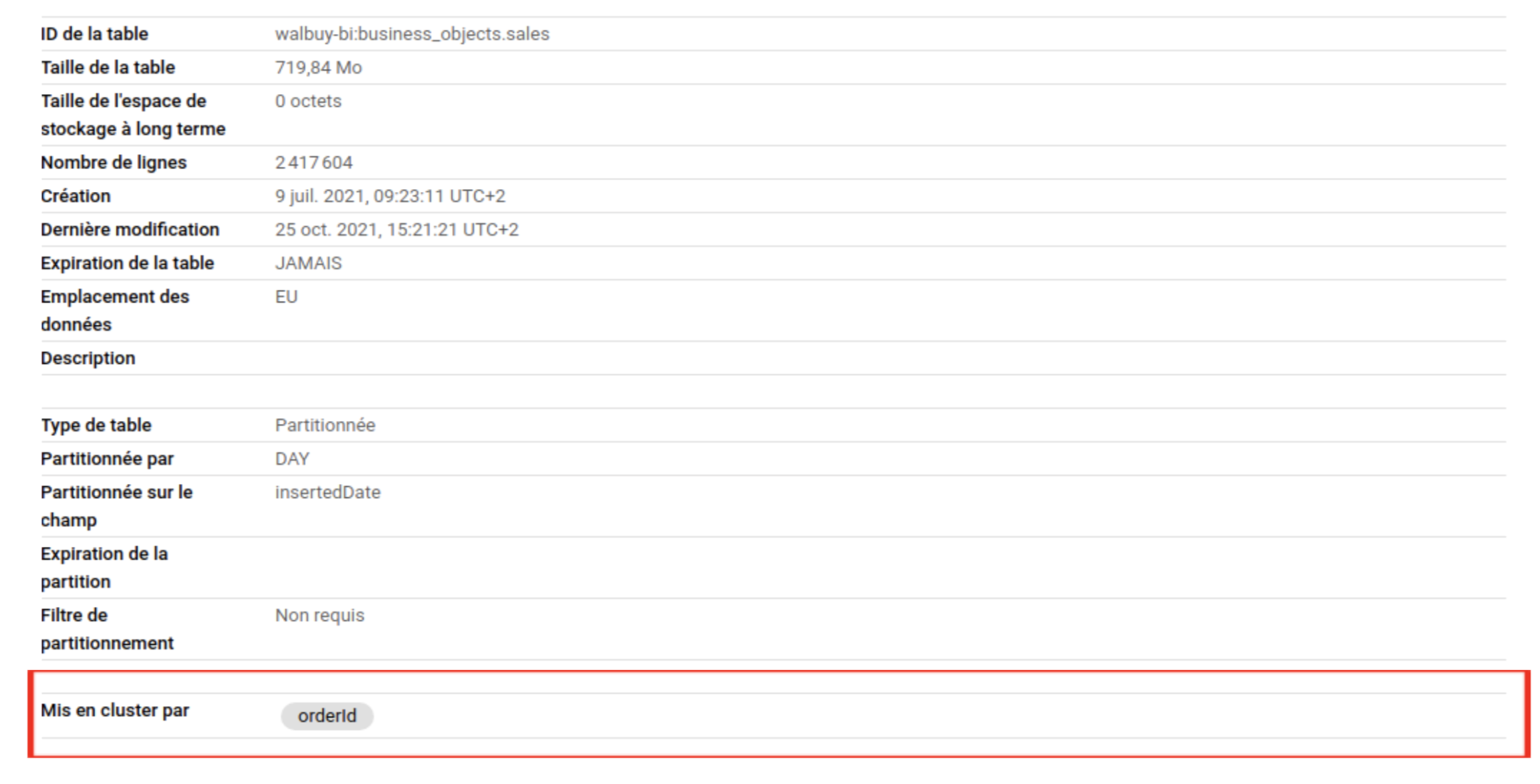
Nous parlerons plus tard de l’intérêt du clustering dans notre cas.
Le clustering peut améliorer les performances de certains types de requêtes, telles que les requêtes utilisant des clauses de filtre et celles agrégeant des données. Lorsque des données sont écrites dans une table en cluster par une tâche de requête ou de chargement, BigQuery trie les données à l'aide des valeurs des colonnes de clustering.
https://cloud.google.com/bigquery/docs/clustered-tables
Fini les UPDATES / DELETE
Comme nous l’avons vu plus haut, nous avons arrêté de faire de la mise à jour de notre donnée, nous faisons systématiquement de l’insert, cependant les delete sont tout aussi long…
Donc fini les deletes, on insérera tout le temps les objets qui remonteront de notre requête vers le Mysql dans le BigQuery.
Gros gain de perf atteint !
Il reste à régler la récupération dans Qlik car maintenant nous avons des doublons dans nos tables (pas très grave, cela peut nous servir d’historique car nous envoyons la data en fonction de la date de mise à jour). Le choix a été fait de créer des vues SQL de dédoublonnage et de passer par ces vues dans Qlik au lieu d’interroger une table directement.
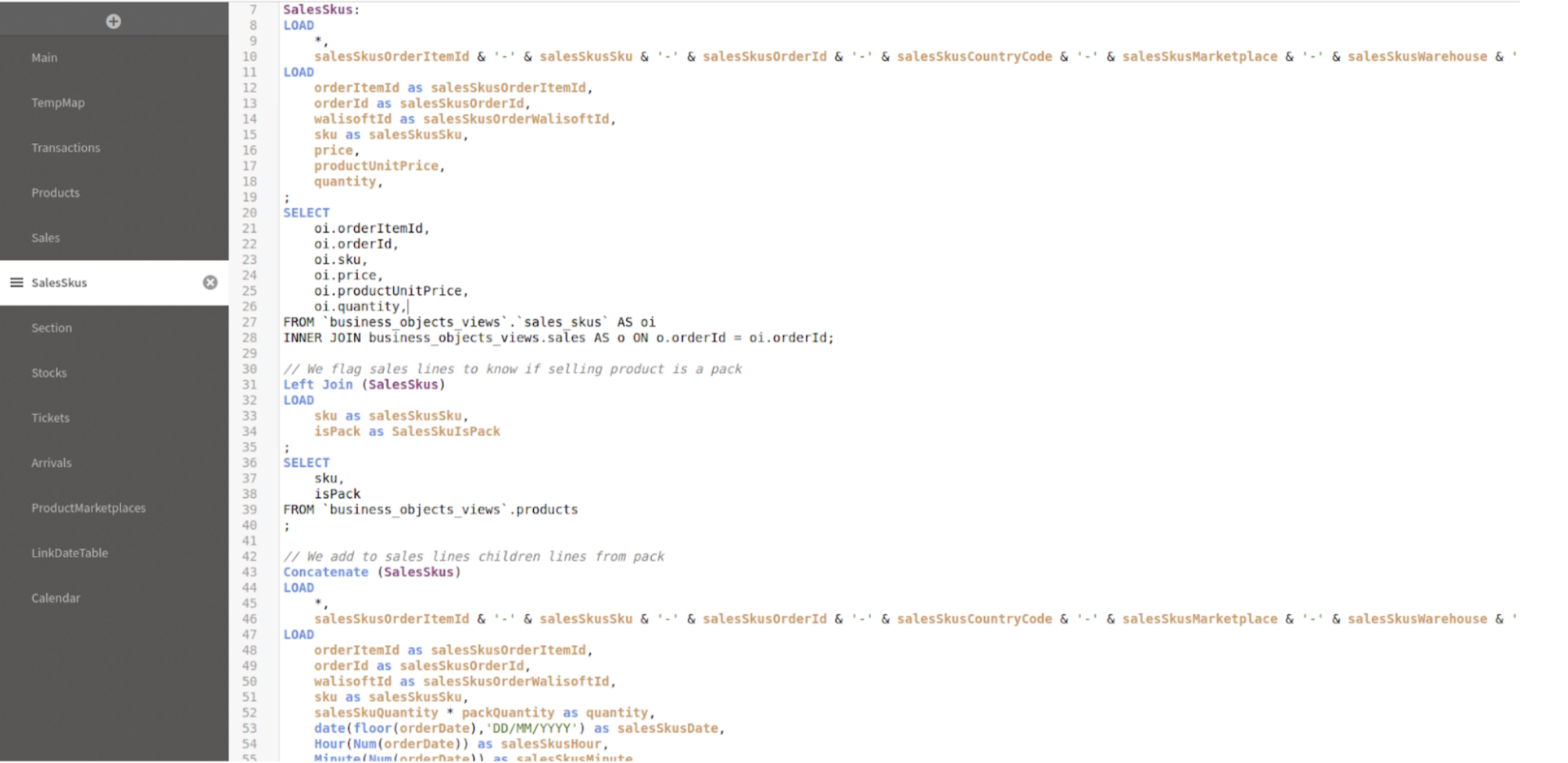
SalesSkus:
<code>LOAD
<code>...
<code>LOAD
<code>...
<code>;
<code>SELECT
<code>...
<code>FROM `business_objects_views`.`sales_skus` AS oi
<code>INNER JOIN business_objects_views.sales AS o ON o.orderId = oi.orderId;
Aperçu d’un script Qlik
-- Remove duplicate orders
<code>WITH<span style="font-weight: 400;"> last_inserted_order </span><span style="font-weight: 400;">AS</span><span style="font-weight: 400;"> (</span>
<code> <span style="font-weight: 400;">SELECT</span>
<code> orderId,
<code> <span style="font-weight: 400;">MAX</span><span style="font-weight: 400;">(insertedDate) </span><span style="font-weight: 400;">as</span><span style="font-weight: 400;"> insertedDate </span><span style="font-weight: 400;">-- insertedDate correspond à la date d’insertion dans BigQuery (d’où la création du partionnement)</span>
<code> <span style="font-weight: 400;">FROM</span><span style="font-weight: 400;"> `walbuy</span><span style="font-weight: 400;">-</span><span style="font-weight: 400;">bi.business_objects`.sales</span>
<code>> <span style="font-weight: 400;">GROUP</span> <span style="font-weight: 400;">BY</span><span style="font-weight: 400;"> orderId </span><span style="font-weight: 400;">-- orderId correspond à l’identifiant unique de la commande (d’où la notion de clustering)</span>
<code>)
<code>SELECT <span style="font-weight: 400;">*</span>
<code>FROM<span style="font-weight: 400;"> `business_objects`.sales s</span>
<code>INNER <span style="font-weight: 400;">JOIN</span><span style="font-weight: 400;"> last_inserted_order</span>
<code>USING<span style="font-weight: 400;"> (orderId, insertedDate);</span>
Vue BigQuery
Stream BigQuery
Avec l’utilisation de requêtes SQL pour mettre à jour notre base de données BigQuery, nous étions obligés de faire des envois de requêtes par lot (paquet de 900 inserts à la fois). Nous avons dû aussi développer un petit moteur de génération de requêtes SQL en fonction d’un objet normalisé en tableau (beaucoup de code = source de bugs).
Avec le stream, plus de notion de batch, on envoie tout ce qui est en attente d’un coup. Le SDK Google prend en paramètre un tableau clef / valeur où la clef est le nom de la colonne et la valeur est la donnée. Donc plus simple!
Avec ce changement nous avons pu tester de streamer un lot de 50000 données à envoyer et cela s’est fait presque instantanément.
La donnée n’est en réalité pas encore intégrée dans la table mais le moteur google est assez puissant pour détecter qu’un stream est en cours et lors d’une requête, il va aller chercher dans la table et dans le stream tampon.
https://cloud.google.com/bigquery/streaming-data-into-bigquery
La mise à jour des data dans BigQuery se fait maintenant presque instantanément à partir du moment où le flux est prêt à être envoyé ou avant nous devions attendre une dizaine de minutes!
Optimisations Qlik
Applications multiple et agrégation
A notre début d’utilisation de Qlik, nous avions une seule et unique Application qui gérait toutes les données via un seul script de chargement.
Afin d’accélérer les temps de chargement, nous avons séparé cette dernière en 4 applications. La grande force de Qlik est sa technologie de stockage de données dans des fichiers vectoriel (format QVD) qui sont lû par les feuilles de calcul pour produire des KPIs.
Le format de fichier est optimisé pour la vitesse de lecture des données à partir d’un script QlikView, mais il reste très compact. Lire des données d’un fichier QVD se fait en général 10 à 100 fois plus vite que d’une autre source de données.
https://help.qlik.com/fr-FR/qlikview/May2021/Subsystems/Client/Content/QV_QlikView/QVD_files.htm
L’agrégation des données depuis des sources différentes est possible dans Qlik via les scripts et c’est ce que nous avons utilisé. Nous avons donc une première application qui va initialiser toutes les données dans un fichier QVD (Nous déclenchons ce script uniquement à l’initialisation et lorsque nous modifions notre schéma). Une deuxième application qui charge certaines données (sous forme d’historique) qui est déclenchée une fois par jour. De la même manière, nous avons une troisième application qui se déclenche toutes les cinq minutes pour les données qui ont besoin d’être fraîches. Les applications 2 et 3 utilisent l’agrégation Qlik et agrègent leurs données dans les QVD créés par l’initialisation.
La quatrième et dernière application est une application avec des feuilles présentant des KPIs, elle utilise directement les fichiers QVD pour construire son modèle de données.
KPI Qlik
Exemple de graph
La business intelligence est un sujet complexe à mettre en place et demande beaucoup de compétences au-delà du développement web (gestion de la Big data avec le data lake, gestion d’un modèle de données pour effectuer des statistiques, assimilation d’un langage propriétaire de requêtage de données, création de graph…).
D’un point de vue technique, nous n’avons pas hésité à faire appel à des experts Qlik et BigQuery pour nous accompagner de la meilleure des manières (au total 2 semaines de formation pour 2 deux personnes). Aujourd’hui nous sommes donc sûr d’utiliser toutes les bonnes pratiques de mise en place d’applications BI, de stockage de données et nous sommes en capacité d’intervenir sur tous les pans de l’application.
Pour finir, cela a complètement changé la vie des personnes qui pilotent l’activité chez Alice’s Garden. Nous pouvons tout de suite identifier les points faibles des différentes stratégies (achat / pricing / marketing / finance…) métier mises en place.
Vous pouvez en savoir plus sur Alice’s Garden grâce à l’article sur notre nouveau projet, grace à la vidéo Happy Developers de Fabien ou au live avec Damien !



