


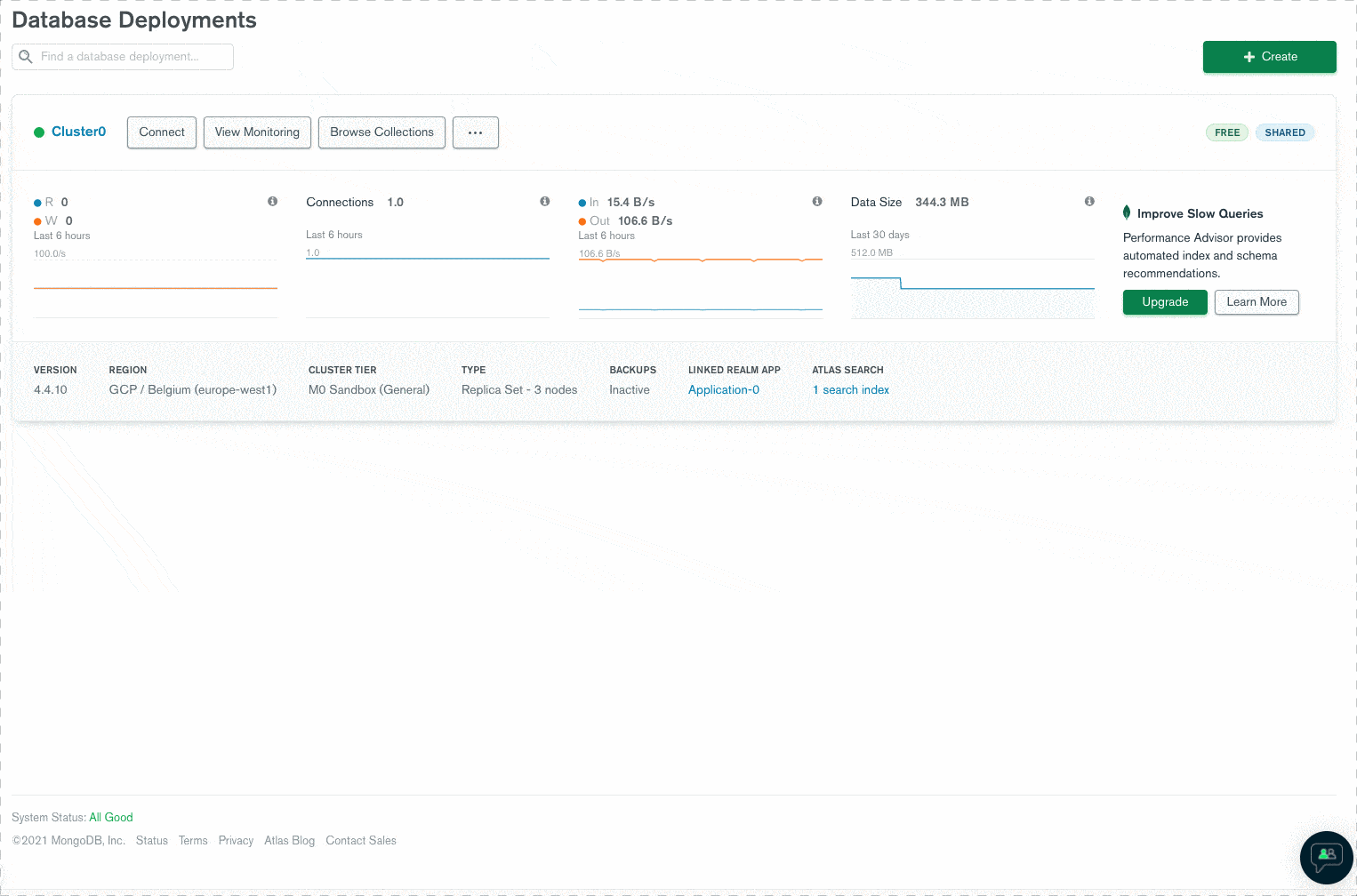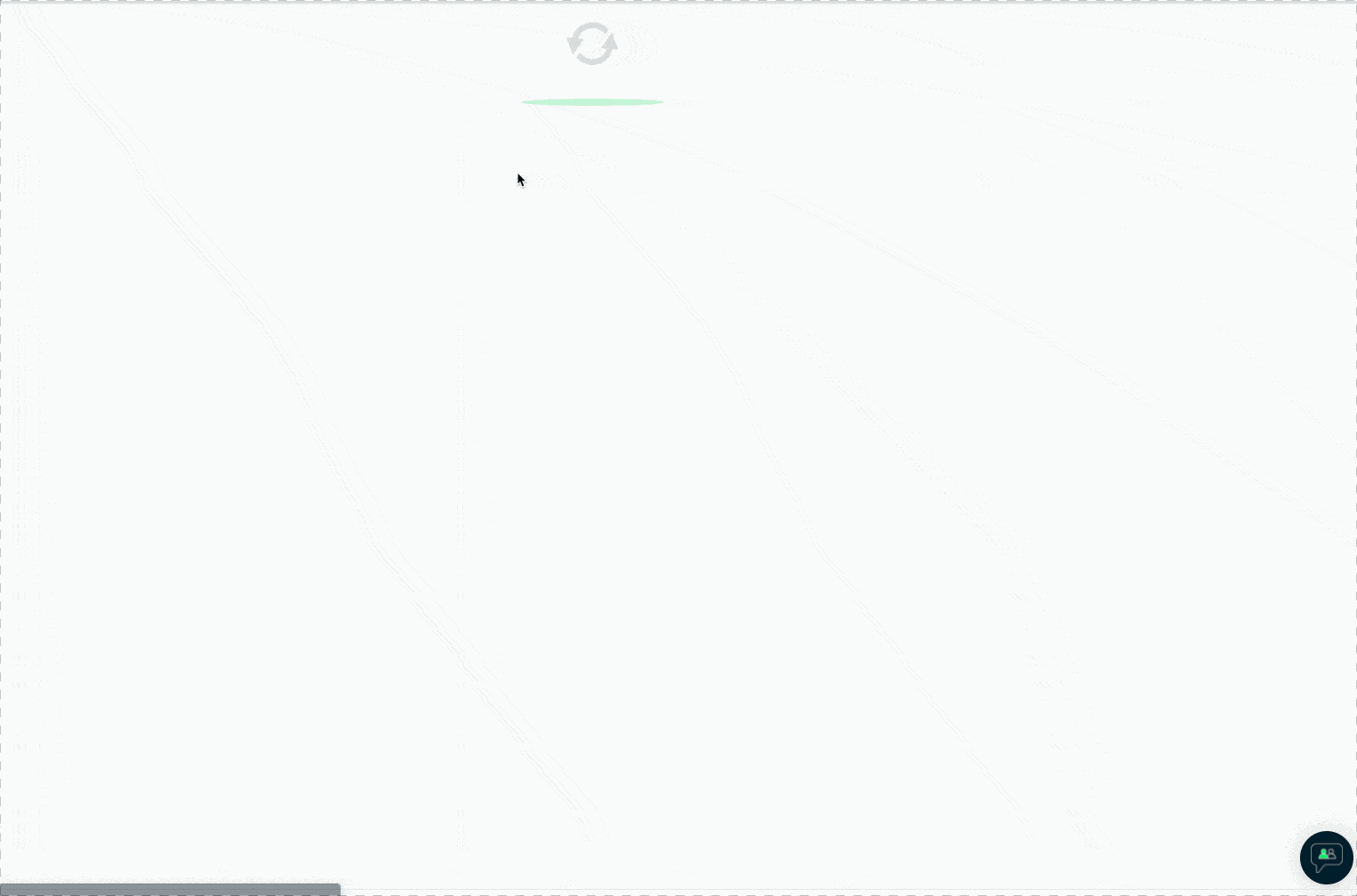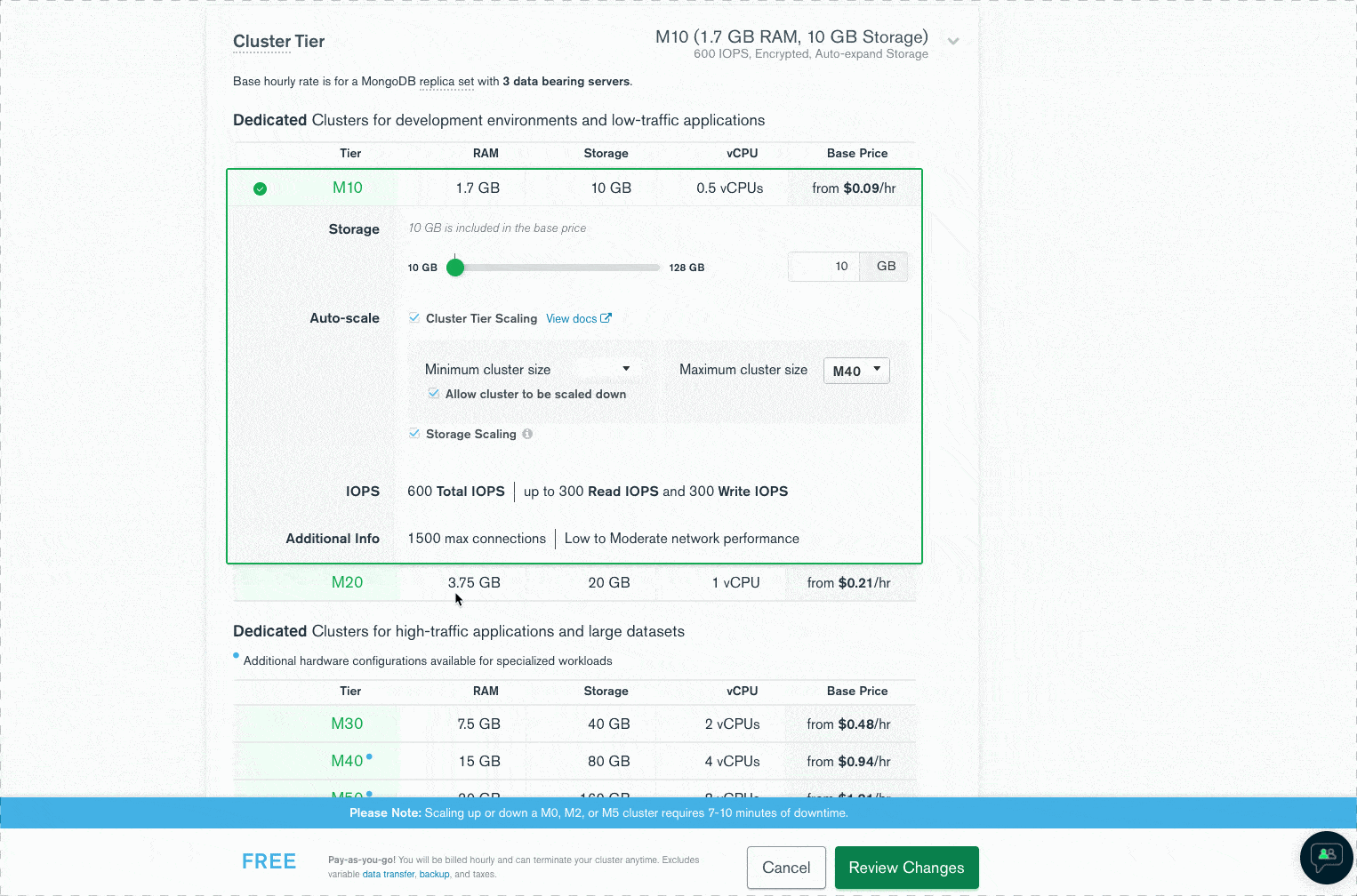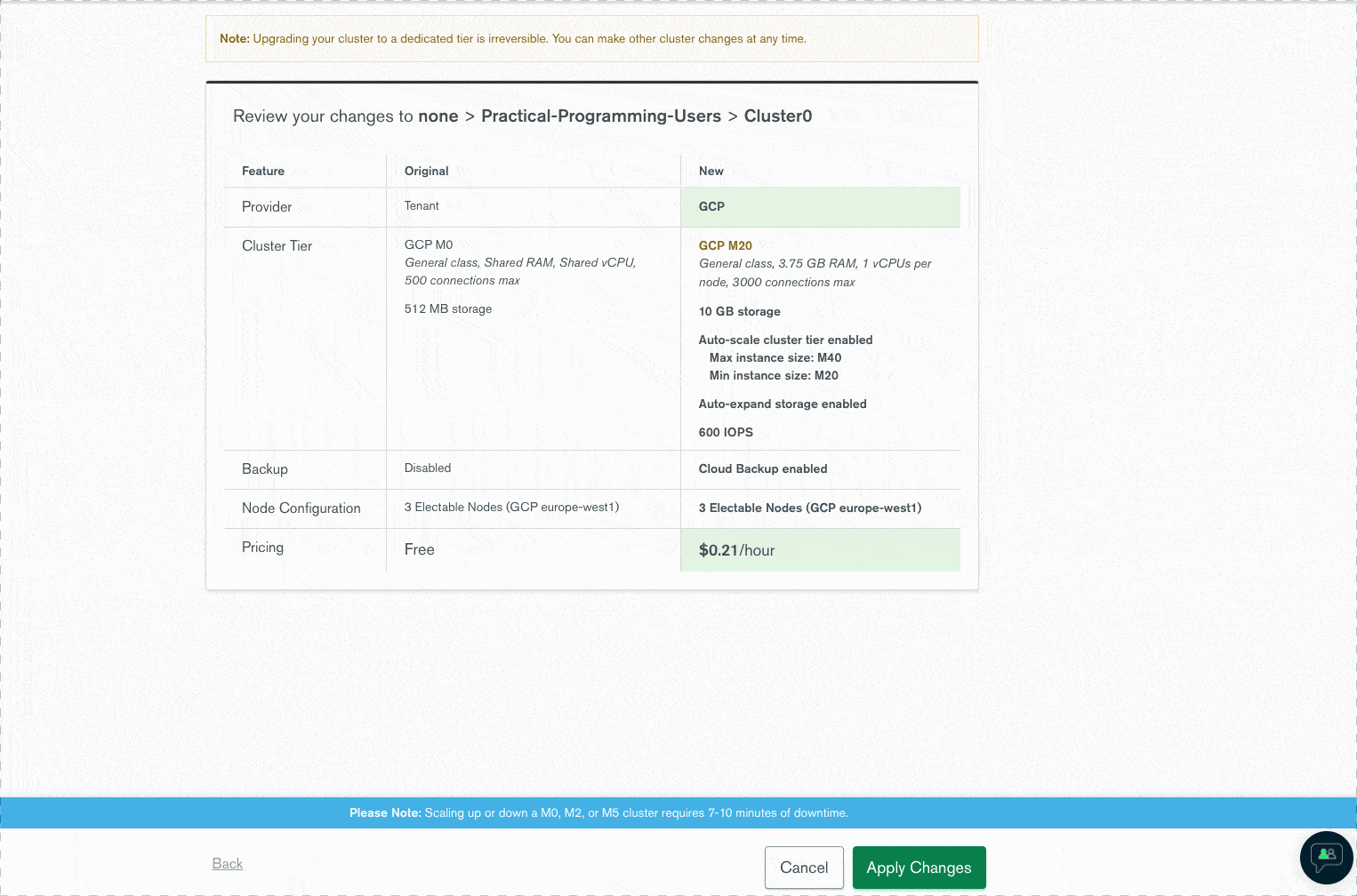
Le Sharding est un des atouts les plus intéressant de MongoDB lorsqu’il s’agit de déployer une application comportant un large jeu de données. Dans cet, découvrez comment tirer toute la valeur du Sharding dans un cluster MongoDB.
Si vous avez lu notre guide sur MongoDB ou si vous avez suivi un de nos tutoriels utilisant MongoDB, vous savez utiliser cette base de données NoSQL pouvant opérer sur un seul replicaSet hébergeant l’ensemble des données.
Lorsqu’une application croît et que le serveur initial n’est plus suffisamment puissant pour répondre aux sollicitations des utilisateurs, la première option est d’envisager un scaling vertical.
En augmentant la RAM, l’espace disque et le CPU, votre serveur est en mesure de répondre à l’augmentation du trafic de la même façon qu’il l’a toujours fait.
Cependant, cette stratégie peut devenir très chère en infrastructure car chaque montée en gamme de votre serveur augmentera son coût d’opération.
Lorsque le scaling vertical n’est plus une option raisonnable, il faut songer au scaling horizontal et utiliser le MongoDB Sharding.
Qu’est-ce que le Sharding
Le concept du scaling horizontal est d’ajouter plus de machines et de les faire travailler conjointement plutôt que de faire monter en puissance une seule machine.
Pour faire travailler conjointement ces machines, il faut pouvoir distribuer la donnée équitablement entre chacune d’entre elles afin que la charge de travail soit absorbée par ces nouveaux serveurs MongoDB.
C’est ce qu’on appelle le Sharding.
Le MongoDB Sharding permet aux développeurs et aux SREs opérant les bases de données de laisser les données croître à leurs guises sans se soucier de devoir toutes les stocker dans un seul serveur.
Les données seront divisées entre les différents serveurs disponibles dans autant de Mongodb Shard qu’il faut pour assurer un bon fonctionnement de la base de données.
Cette architecture s’appelle le Sharded Cluster, où chaque Shard va disposer de son propre replicaSet afin d’assurer la disponibilité et la résilience pour les données qu’il contient.
Quand utiliser MongoDB Shard
Créer un cluster shardé sur MongoDB ajoute une couche de complexité à votre application et il faut s’assurer que le coût humain que va générer cette complexité soit plus intéressant que d’autres stratégies plus simples.
Est-ce que le scaling vertical est devenu trop cher ?
Le premier indice qui devrait vous inciter à considérer le sharding est la facture qui serait engendrée par du scaling vertical.
Si vous utilisez MongoDB Atlas ou MongoDB via un cloud provider, monter en puissance votre machine se fait en quelques clics et ne génère pas d’indisponibilité.
Sauf que cette montée en puissance d’une machine a un coût qui n’est pas linéaire.
Arrivé à une certaine taille, pour doubler la taille de la RAM et la puissance du CPU vous coûtera 10 fois plus cher que le forfait actuel.
Dans ce cas-là, le coût d’infrastructure devient dissuasif et le scaling horizontal va devenir indispensable pour continuer à suivre la croissance de l’application.
Le volume total de données est-il toujours acceptable pour un seul serveur ?
Dans le cas où votre application produit de plus en plus de données, vous arriverez à un stade où vous aurez besoin d’augmenter le volume de stockage disponible pour votre base de données.
Si vous travailliez jusque-là avec 2 téraoctets dans un seul replicaSet, il est encore acceptable de rassembler toutes les données sur un même disque.
En revanche, si vous augmentez votre volume et que vous atteignez 60 téraoctets, même en ayant une capacité totale de stockage de 80 téraoctets disponible sur votre cluster, vous allez vous heurter aux problèmes suivants:
- Si votre jeu de donnée atteint 60 To, vos sauvegardes feront cette taille et seront d’autant plus lentes à être générées.
- Restaurer un cluster de 60 To est 30x plus lent qu’un cluster de 2To.
- Vos index seront plus lourds et auront besoin de plus de RAM afin de fonctionner correctement.
Ces limites vont affecter significativement votre capacité à restaurer vos données s’il y avait un rollback à effectuer sur une partie de vos données.
Comment sont distribuées les données entre les serveurs ?
Architecture d’un cluster MongoDB Sharding
Lorsqu’un Sharded Cluster a distribué les données sur plusieurs groupes de serveurs, le moteur de base de données a besoin de savoir où chercher la donnée lorsque celle-ci est requêtée par un client.
Cette mission est prise en charge par le processus appelé mongos.
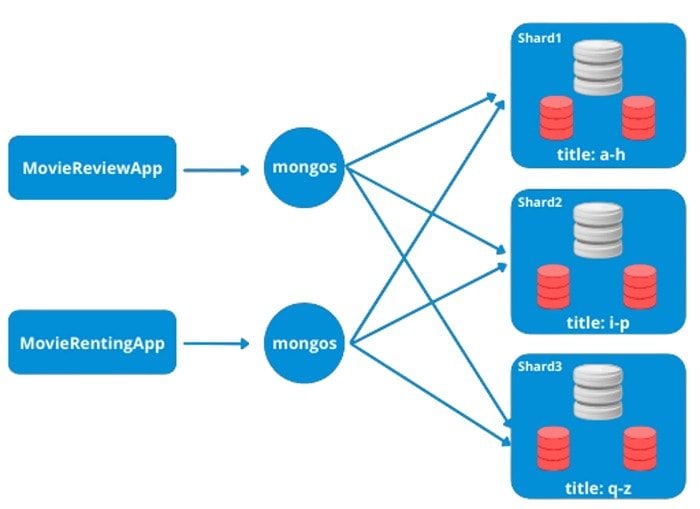
Dans ce cas, les données des films sont réparties sur 3 shards suivant la première lettre du titre.
Mongos: le routeur de MongoDB
Le process mongos va se servir des metadata concernant le MongoDB Sharded Cluster afin de savoir où envoyer la requête.
Dans notre exemple, chaque application va se connecter à un mongos et envoyer sa requête. Si la requête contient le champ « title », mongos va savoir dans quel shard se trouve la donnée. Si en revanche la requête ne contient pas le champ « title », le process mongos va envoyer la requête sur les trois mongodb shards, fusionner les résultats et les renvoyer au client.
Dans le cas d’un Sharded Cluster, avoir un routeur mongos est obligatoire. Toutefois, pour améliorer la disponibilité et la scalabilité de votre application il est également suggéré d’avoir plusieurs instances mongos.
Si vous administrez vous-même votre cluster MongoDB, une bonne pratique est de déployer un mongos sur chaque serveur hébergeant votre application. Vous réduisez ainsi les temps de latence réseau entre l’application et le routeur mongos.
Si vous utilisez MongoDB Atlas pour votre MongoDB Sharded Cluster, celui-ci déploiera automatiquement un routeur mongos pour chaque mongo shard. Si votre cluster est distribué sur plusieurs régions géographiques, vous pourrez définir où chaque driver MongoDB devra se connecter afin d’être au plus près du routeur mongos et proposer les meilleures performances.
Les ConfigServers
Pour que mongos soit capable de savoir dans quel shard se trouve la donnée recherchée, il repose sur les configServers.
La répartition des données étant faite dynamiquement, il se peut que MongoDB redistribue les documents dans différents shards afin que ceux-ci gardent une taille similaire.
Dans notre exemple, s’il y a un nombre plus important de films qui commencent par la lettre « W » au point que le Shard 3 devienne plus gros que les deux autres, les configServers vont déplacer les documents contenant les films commençant par les lettres I et J du second shard vers le premier shard et ceux commençant par Q jusqu’à ceux commançeant par T dans le Shard 2.
Pour que les instances mongos soit au courant de ces changements de place lors des futures requêtes, ces derniers feront des requêtes auprès des différents ConfigServers afin d’avoir la bonne répartition des données.
Les configServers sont déployés dans un replicaSet, de la même façon que des serveurs de données mongod avec la même réplication. Ces configServers peuvent être déployés sur plusieurs régions afin d’assurer les meilleures performances pour les instances mongos.
La Shard Key
La Shard Key (ou clé de sharding) est le champ indexé que MongoDB utilisera pour répartir les documents entre les différents mongo shard de votre cluster.
Il sera donc obligatoire de créer un index autour de votre champ que vous souhaitez utiliser comme clé de sharding.
Dans le cas de notre exemple de base de données sur les films, la clé de sharding choisie est « title ». Les configServers vont définir les groupements de données suivant cette Shard Keys puis diviser ces blocs (appelés officiellement des Chunks) entre les différents shards.
Pour assurer une bonne performance à l’écriture (insert ou update), les processus mongos ont absolument besoin de savoir la valeur liée à la clé de sharding pour pouvoir réaliser l’opération.
C’est pourquoi, le champ choisi comme Shard Key va devenir un champ obligatoire pour tous les documents existants et à venir dans la collection.
Dans les requêtes de lecture de données, la clé de sharding n’est pas obligatoire, toutefois elle devrait être présente dans la majorité des requêtes afin de maintenir un bon niveau de performance.
Sachez également qu’une fois que vous aurez défini votre Shard Key, vous ne pourrez plus la modifier.
Non seulement le choix de la clé est définitif, mais la valeur de ce champ dans un document devient immuable.
Dans notre exemple, une fois que j’ai créé un film avec son titre, je ne pourrais pas changer ce champ du document. Il faudrait l’effacer et le recréer si besoin.
Enfin, vous ne pouvez pas revenir en arrière et « dé-sharder » votre collection.
Les Chunks
Les Chunks représentent les blocs de données contenant plusieurs documents et répartis sur les différents mongo shard disponible sur le cluster.
Dès l’instant où on définit une clé de sharding, mongodb crée un premier Chunk contenant l’ensemble des documents:
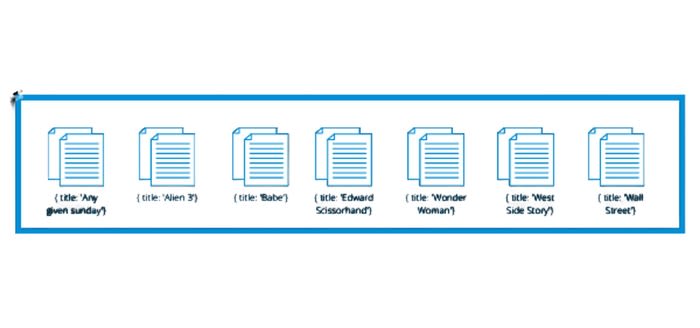
Dans ce cas, notre Key Space, les règles déterminant la répartition des documents, démarre de la lettre « A » à la la lettre « Z ».
Les chunks peuvent avoir une taille maximum de 1Mo à 1024Mo. Passé la taille maximum, les configServers vont procéder à un rééquilibrage des Chunks et redistribuer les documents dans les différents shards.
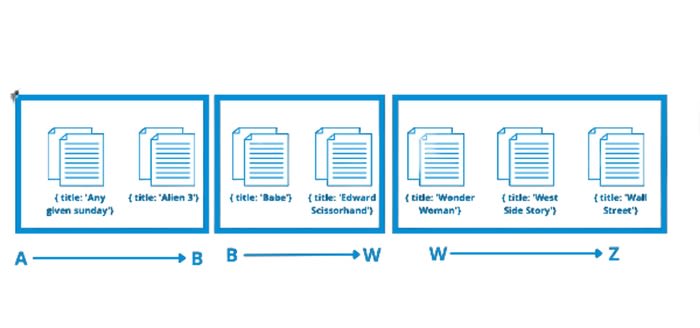
Un document ne peut vivre que dans un seul shard suivant la répartition des chunks et la shard key. Ce qui veut dire que le choix de cette dernière peut se révéler bloquant et imposant une limite au scaling horizontal que propose le mongodb sharding.
Par exemple, le choix de sharding par la première lettre du titre limitera le sharding à 26 shards. En revanche, en choisissant une shard key hashée à partir du titre, on s’affranchit de cette limite et on laisse mongoDB définir le nombre de shards sans limite.



