


Pour cet article de la série Web Scraping, nous allons voir comment récupérer les données du site du journal Le Monde en créant un scraper PHP
Cet article est le troisième de notre série Web scraping : le guide complet avec tutoriels. Il est fortement recommandé de lire les deux précédents articles avant celui-ci : Data scraping et Web scraping : la vraie définition et Web scraping : quels langages et technologies choisir.
Pour commencer simple mais avec un cas d’usage concret, nous allons créer un programme qui va extraire les articles de la page d’accueil de LeMonde.fr.
Peu importe la technologie que vous allez choisir pour coder, vous devez forcément réaliser un travail préliminaire pour conceptualiser votre programme de web scraping et établir son mode de fonctionnement. Je vais vous montrer ma méthodologie.
Travail préliminaire
Quand on veut se lancer dans l’écriture d’un programme de web scraping, la première chose à faire est de se rendre sur le site ciblé, ici LeMonde.fr.
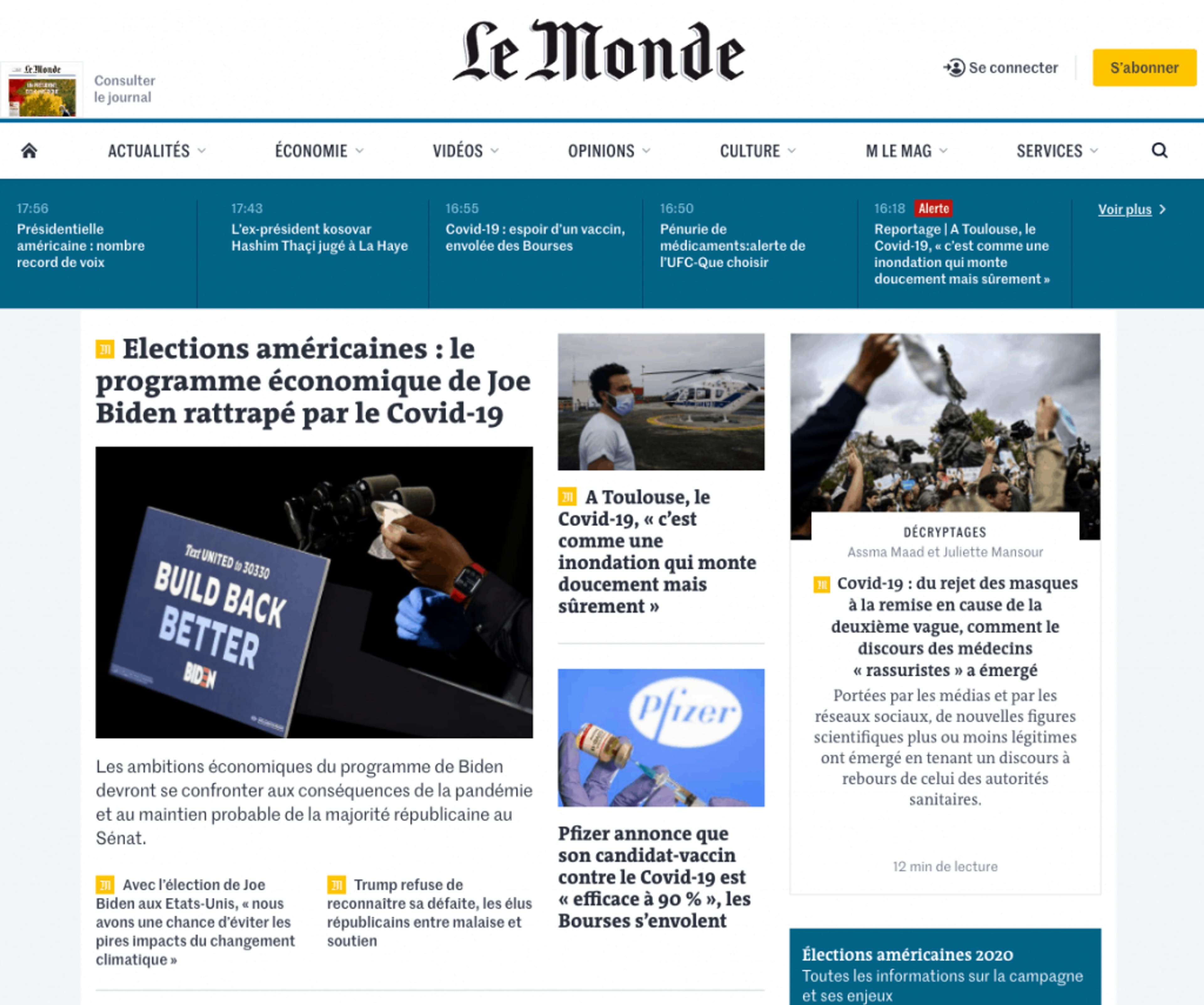
Dans notre cas, l’objectif de notre programme est simple : extraire tous les articles de la page d’accueil.
Nous allons donc observer le code HTML de la page pour en comprendre la structure et repérer un pattern qui nous permettra de cibler tous les articles de la page d’accueil en faisant le moins d’efforts possibles. En web scraping, les développeurs utilisent la plupart du temps les sélecteurs CSS et/ou les sélecteurs XPath pour sélectionner un ou plusieurs éléments sur la page et en extraire le contenu.
Exemples de sélecteurs CSS pour le web scraping
Il existe de nombreux sélecteurs CSS et chaque élément HTML d’une page peut être manipulé par de nombreux sélecteurs différents. Ce qui est important est de choisir le bon sélecteur pour sélectionner les éléments que vous avez besoin d’extraire : le sélecteur ne devra pas rater des éléments, ni inclure des éléments dont vous n’avez pas besoin.
La liste ci-dessous est un extrait traduit de la liste de w3schools qui proposent également un testeur de sélecteur pour vous aider à comprendre leur fonctionnement.
Analysons maintenant la structure du code de la page d’accueil du site ciblé à l’aide des outils de développement de votre navigateur pour trouver le bon sélecteur qui va nous permettre de sélectionner tous les articles de la page et aucun autre élément.
Analyse de la structure HTML pour le web scraping
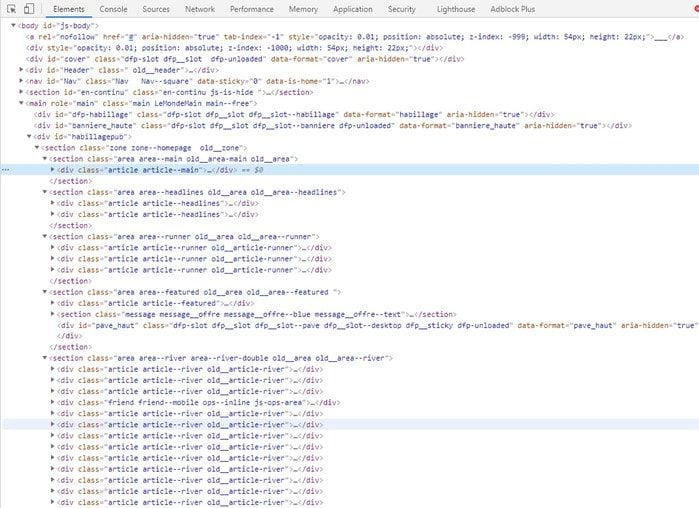
Une bonne façon de trouver rapidement un sélecteur avec notre navigateur est de faire un clic droit sur un des éléments ciblés (dans notre cas, un article) et de cliquer sur inspecter. Les outils de développement nous montrent alors l’élément HTML et on peut dès lors chercher des patterns ou répétitions dans le code qui nous permettent de trouver un sélecteur. Par exemple : les éléments que l’on cible sont tous de la même classe, ont le même attribut ou le même parent etc.
Sur le site du Monde, on peut voir par exemple que chaque article semble être contenu dans un élément div de classe article comme le montre la capture ci-dessous :
Essayons donc de sélectionner tous les éléments div de classe article avec le sélecteur CSS div.article en le tapant dans la barre de recherche des outils de développement :
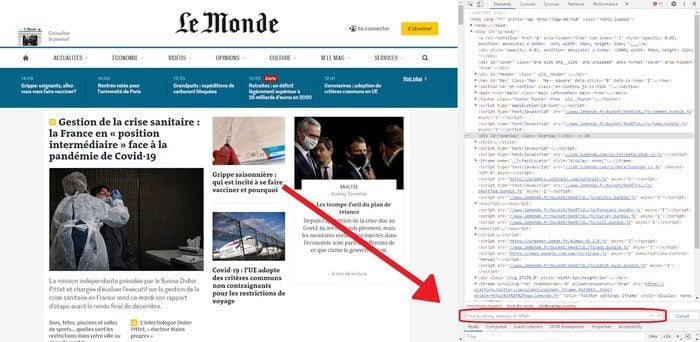
Pour tester un sélecteur CSS ou XPath sur le code d’une page dans Google Chrome, il faut ouvrir les outils de développement avec F12 puis faire apparaître la barre de recherche (entourée en rouge sur la capture ci-dessus) avec Ctrl+F.
Le navigateur nous montre ensuite le nombre d’éléments sélectionnés (ici 81) et nous pouvons appuyer successivement sur Entrée pour voir défiler tous les éléments sélectionnés.
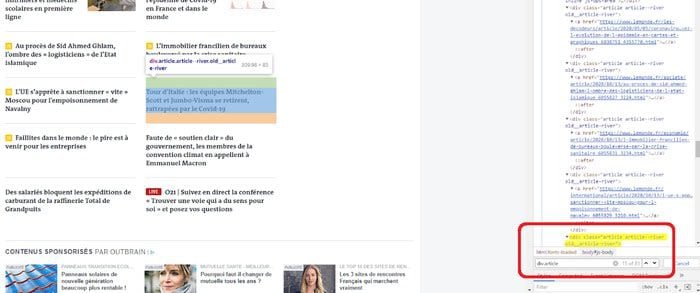
Le sélecteur div.article semble bien nous sélectionner tous les articles de la page d’accueil. En réalité, le sélecteur n’est pas le bon pour notre programme car un peu plus loin sur la page, plusieurs articles sont en réalité contenus dans un élément div.article comme le montre la capture ci-dessous :
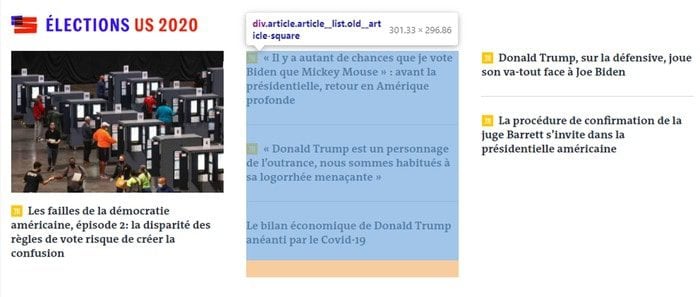
Nous devons donc affiner notre sélecteur CSS pour nous permettre d’obtenir également ces articles à l’intérieur de ces éléments. Sinon, notre scraping produira des erreurs car il considérera cet élément comme un seul et même article alors qu’il en contient en réalité 3.
Chaque article de presse sur Le Monde étant une page distincte, on peut logiquement considérer que chaque article sur la page d’accueil sera accessible par un lien.
Essayons donc d’accéder à chaque élément <a> contenu dans un élément <div class=”article”> avec le sélecteur div.article > a.
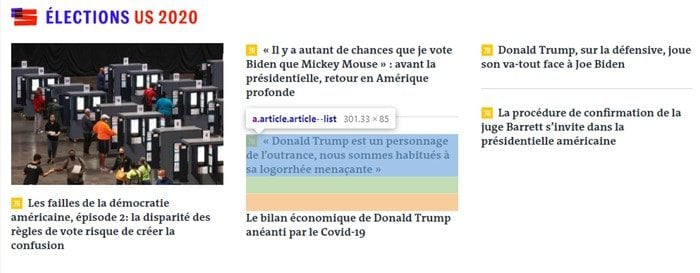
Ça fonctionne ! Nous avons maintenant 151 résultats : il y a bien 151 articles sur la page d’accueil du site.
Parfois, dans certains cas complexes, nous sommes jamais sûrs du sélecteur que nous avons choisi. Une petite astuce que j’utilise consiste à tester directement dans la console du navigateur notre sélecteur avec un petit script JavaScript. Ici, je vais tester notre sélecteur avec le code suivant :
var selector = 'div.article > a';var list = document.querySelectorAll(selector), i;for (i = 0; i < list.length; ++i) { console.log(list[i].getAttribute('href'));}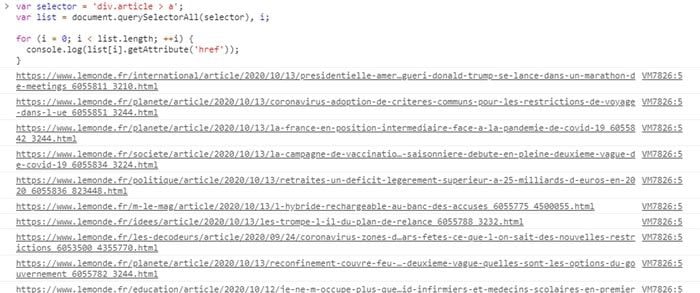
Ce code nous imprime bien les URL de tous les articles de la page d’accueil, nous pouvons donc choisir ce sélecteur pour notre programme de scraping.
Nous savons donc maintenant comment va fonctionner notre programme de web scraping :
- Fetching : Il va se connecter à la page d’accueil du site et en télécharger le code HTML
- Parsing : Il va parser le code HTML à l’aide du sélecteur CSS div.article > a pour extraire les liens vers chaque article
- Stockage : Il va stocker les titres et les URL des articles dans un fichier CSV
À nos IDEs !
Exemple de code web scraping en PHP avec Goutte
Si vous êtes passé directement à cette partie sans lire les précédentes, je vous conseille au moins de lire la partie précédente “Travail préliminaire”.
Pour suivre ce guide, vous aurez besoin de la librairie de web scraping Goutte que vous pouvez installer dans le dossier de votre projet avec la commande suivante (Composer requis) :
composer require fabpot/goutteVous aurez également besoin d’un serveur local pour lancer vos scripts PHP.
Créons un nouveau fichier index.php, invoquons le fichier Autoload de Composer et Goutte
<?php require __DIR__ . "/vendor/autoload.php"; use Goutte\Client;Créons un nouveau client et téléchargeons la page d’accueil du site visé :
$client = new Client(); $crawler = $client->request('GET', 'https://www.lemonde.fr');Itérons à travers notre sélecteur d’articles pour extraire les données qui nous intéresse et les imprimer à l’écran avec print_r() – notez l’utilisation de trim() pour nettoyer le nom de l’article d’espaces non voulus :
$crawler->filter('div.article > a')->each(function ($node) use ($out) { $url = $node->attr('href'); $nom = trim($node->filter('.article__title')->text()); print_r([$nom,$url]); });Lançons notre script et consultons les résultats :

Notre script PHP a réussi a extraire le titre et les liens pour chaque article
Tout fonctionne comme prévu, les résultats sont très propres
Ajoutons maintenant quelques lignes pour télécharger automatiquement un fichier CSV contenant les résultats de notre web scraping. Le code final ressemble à ceci :
<?php header('Content-Type: text/csv'); require __DIR__ . "/vendor/autoload.php"; use Goutte\Client; $client = new Client(); $crawler = $client->request('GET', 'https://www.lemonde.fr'); $out = fopen('php://output', 'w'); $crawler->filter('div.article > a')->each( function ($node) use ($out) { $url = $node->attr('href'); $nom = trim($node->filter('.article__title')->text()); fputcsv($out, [$nom,$url]); }); fclose($out);?>Consultons maintenant le fichier CSV pour observer les résultats :
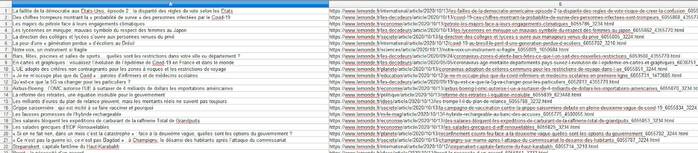
Les titres et les urls sont bien consolidés dans un fichier CSV
Pour constater les différences entre chaque langage au niveau du web scraping, je vous conseille de consulter les autres tutoriels :
Sinon, vous pouvez passer directement au tutoriel avancé de web scraping de web app avec Puppeteer.



