
Xavier, membre de la communauté de blogueurs JobProd.
Parmi les systèmes de gestion de version existant, Git fait parti des favoris depuis quatre ou cinq ans. Créé en 2005 par Linus Torvald, Git est un système de gestion de version très puissant, et malheureusement assez complexe à appréhender dans sa totalité, surtout pour les développeurs juniors ou habitués à d’autre systèmes, comme par exemple SVN.
Reçois en 24H les + belles offres tech matchant avec ta recherche
Je vous propose donc de faire le point sur Git et d’en comprendre l’essentiel afin de pouvoir l’utiliser au jour le jour.
Le maillon de base : le commit

L’élément principal de Git est le commit. Tout dans Git est fait pour gérer ces objets, qui ne sont rien de plus qu’une description de l’état de chacun des fichiers dans le projet.
Un commit est identifié par un numéro unique, pas très user friendly, comme par exemple 1882fdda054a2c4ac783787c08c67a995872a5b5. Un commit contient également un message écrit par le développeur pour décrire les modifications apportées, ainsi que la date et le nom de l’auteur du commit.
Un commit va également retenir l’identifiant de son (ou ses) parent(s). C’est pour cela que je parle de maillon : les commits s’organisent sous une forme de chaîne, partant du commit 0 (celui présent à la création d’un projet).
Plusieurs chaines : les branches
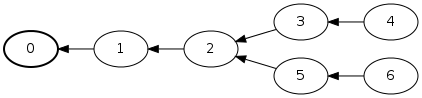
L’intérêt des commits, c’est que plusieurs d’entre eux peuvent avoir le même parent. Le principe des branches est né de cette fonctionnalité, et permet d’avoir plusieurs chaines de commits (les branches) partant d’un ancêtre commun.
Chaque branche permet de faire des développement parallèles, et peuvent, à un moment donné, être fusionnées à nouveau en une seule branche. Et en réalité, une branche n’est simplement qu’un pointeur vers le dernier commit dans une chaine donnée.
Le contenant : dépôt et espace de travail
Le dépôt (repository en anglais) désigne l’historique des commits, c’est à dire l’intégralité des modifications apportées aux fichiers gérés par Git.
L’espace de travail correspond lui aux dossiers et fichiers de votre projets, ceux que vous avez l’habitude de manipuler quotidiennement.
Entre les deux va se trouver l’index, un registre qui va garder en mémoire les modifications que vous avez sélectionnées pour le prochain commit.
Reçois en 24H les + belles offres tech matchant avec ta recherche
Un exemple concret
Simplement avec ces notions, il est possible de travailler en local, et de gérer les changements apportés à des fichiers. Je m’en vais donc vous proposer un exemple concret d’utilisation de git.
Pour initialiser un dépôt dans un espace de travail, utilisez la ligne de commande suivante :
$ git init
Initialized empty Git repository in /home/xgouchet/Perso/workspace/.git/
Pour connaitre l’état de l’espace de travail et de l’index, utilisez la commande status :
$ git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# Main.java
# Pojo.java
nothing added to commit but untracked files present (use "git add" to track)
Le résultat de la commande status nous indique que nous sommes sur la branche master (la branche par défaut dans Git), que nous somme sur le commit initial (sans aucun parent), et que deux fichiers ont été modifiés dans l’espace de travail sans être ajoutés à l’index.
Remedions à cela et ajoutons notre main à l’index, comme ceci :
$ git add Main.java
$ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached ..." to unstage)
#
# new file: Main.java
#
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# Pojo.java
Le fichier Main.java a bien été ajouté à la liste des modifications à prendre en compte pour le prochain commit. Continuons en faisant ce commit :
$ git commit -m "Mon premier commit"
[master (root-commit) ac3b917] Mon premier commit
0 files changed
create mode 100644 Main.java
L’argument -m permet de spécifier le message associé au commit. Faisons un dernier status.
$ git status
# On branch master
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# Pojo.java
nothing added to commit but untracked files present (use "git add" to track)
Nous pouvons également créer une nouvelle branche à partir du dernier commit. La commande git branch permet de créer cette branche, puis git checkout change l’espace de travail pour refléter l’état de la branche désiré.
$ git branch develop
$ git checkout develop
Switched to branch 'develop'
Enfin la commande git log permet de visualiser l’historique de commit sur la branche actuelle.
Reçois en 24H les + belles offres tech matchant avec ta recherche
Un repo, deux repo, trois repo, …
Pour l’instant nous avons vu le cas d’un dépôt autonome, mais l’intérêt de Git réside également dans la possibilité de synchroniser plusieurs dépôts distants, afin que plusieurs développeurs puissent synchroniser son travail.
Il est possible de définir dans un dépôt une liste de dépôts distants. Puis il est possible de synchroniser les commits entre les dépots distants et le dépot local. Le plus important à savoir est que lors de la synchronisation, qu’elle soit montante (push) ou descendante (pull), les deux dépôts doivent avoir un commit parent en commun.
Gestion des conflits
Dans un monde idéal, tout se passe bien, malheureusement il arrive que des conflits arrive. Dans l’exemple ci dessous, deux développeurs sont partis du même commit (le 2). L’un d’entre eux à créé les commits 3 et 4, qu’il a envoyé sur le serveur commun. Le second a créé les commits 5 et 6 et au moment d’envoyer lui aussi ses modifications reçoit un message d’erreur. En effet son historique n’est plus synchrone avec celui du repo distant.

Si les commits du second developeut ne touchent pas aux mêmes fichiers que le premier dévelopeur (ou si ils modifient le même fichier mais à des endroits différents), alors il est possible d’avoir recours à un rebase. Le rebase permet de changer le parent du commit 5 pour qu’il pointe vers le commit 4.

Par contre si les commits touchent aux même parties du code, alors il est nécessaire de fusionner les deux chaines de commits à la main.

Un exemple concret (bis)
Lorsque l’on veut travailler avec un dépôt distant, il existe plusieurs façon de faire. Il est possible de créer un clone d’un dépôt distant existant, ce qui va créer le dépôt local :
$ git clone https://website.tld/path/to/remote/repo.git
Cloning into 'repo'...
remote: Reusing existing pack: 318, done.
remote: Total 318 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (318/318), 630.47 KiB | 299 KiB/s, done.
Resolving deltas: 100% (103/103), done.
$ cd repo
$ git status
# On branch master
nothing to commit (working directory clean)
La seconde méthode est de lier un dépôt local existant (comme celui de notre premier exemple) et de le lier au dépôt distant. Chaque dépôt distant possède un nom l’identifiant (par convention, le dépôt distant principal s’appelle origin, mais il est possible d’avoir plusieurs remote).
$ git remote add origin https://website.tld/path/to/remote/repo.git
Une fois notre dépôt lié à un autre dépôt, il y a principalement trois commandes à connaitre. La plus importante, git fetch, permet de mettre à jour le dépôt afin qu’il connaissent l’état du dépôt distant.
$ git fetch
remote: Reusing existing pack: 318, done.
remote: Total 318 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (318/318), 630.47 KiB | 61 KiB/s, done.
Resolving deltas: 100% (103/103), done.
From website.tld/path/to/remote/repo
* [new branch] master -> origin/master
Ici le fetch a détecté l’existance d’une branche master sur le dépôt distant (origin) et a créé la branche correspondante en locale.
La commande git pull permet de mettre à jour la branche courante locale à partir de celle présente sur le dépôt distant.
Ici deux cas de figure sont illustrés : dans le premier cas, je n’ai pas de commit en local, et la commande applique ce que l’on appelle un fast forward, c’est-à dire que les nouveaux commits sur le dépôt distant vont venir s’ajouter à mon index, rendant les deux dépôts synchrones.
$ git pull --rebase origin master
Updating 9d447d2..f74fb21
Fast forward
Dans le second cas, j’ai déjà des commits en locals, ce qui pourrait causer un conflit. le fait d’ajouter --rebase indique à git qu’il doit tenter de faire un rebase, c’est à dire qu’il va défaire mes commits en local, appliquer les commits distants puis tenter d’appliquer à nouveau les modifications que j’avais en local.
$ git pull --rebase origin master
First, rewinding head to replay your work on top of it...
Applying: Initial commit
Enfin, git push au contraire ajoute nos nouveaux commits à la branche correspondante sur le dépôt distant. Pour faire un push propre il est toujours nécessaire de faire un pull avant pour être sur qu’il n’y aura pas de conflit sur le dépôt distant. En effet, si un conflit arrive il n’y aura personne pour le résoudre sur la machine distante.
$ git push origin master
Counting objects: 9, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 531 bytes, done.
Total 5 (delta 4), reused 0 (delta 0)
remote: Resolving deltas: 100% (4/4)
remote: Processing changes: refs: 1, done
To website.tld/path/to/remote/repo
1037995..731a007 master -> master
Conclusion
Git, de prime abord, peut très vite paraitre complexe tant il y a de concepts à comprendre. Je n’ai ici fait qu’une introduction qui explore les principales fonctionnalités sans rentrer en profondeur. Le plus important est de comprendre les concepts de commit, dépôt et index, le reste viendra au fur et à mesure de l’utilisation de l’outil.
Reçois en 24H les + belles offres tech matchant avec ta recherche
Xavier
Geek, Android-ophile, curieux de nature et aimant partager mes connaissances, je baigne dans le monde de la programmation depuis un bon moment, et aujourd’hui je suis principalement porté sur les technologies mobiles, et principalement Android.
J’apprécie autant découvrir de nouvelles techniques, développer des bouts de codes pour générer des images, échanger sur divers sujets techniques, que partager mes connaissances par quelque moyen que ce soit.
Aujourd’hui, je passe mon temps entre Deezer, où je fais partie de l’équipe Android, mes propres applications Android Open Sources, et mes trajets quotidiens en train, entre ma campagne percheronne et Paris.
En savoir +





Merci pour ces précisions, je comprend mieux pourquoi un commit n’implique pas automatiquement une mise à jour du dépôt distant.
Et vive le Perche 😉
Bonjour. Ce tutoriel est très réussi. Moi, j’ai réussi à comprendre les fonctionnalités avancées du Git grâce à des vidéos sur http://www.alphorm.com/tutoriel/formation-en-ligne-git-fonctionnalites-avancees. En tout cas, merci pour ce partage.