


Si vous avez suivi notre guide Node.js, vous savez que Node repose sur trois bases fondamentales : le moteur JavaScript V8 de Google, une API de bas niveau nommée libuv et une boucle d’événement plus communément appelée event loop. Ces trois éléments fonctionnent en complémentarité pour permettre de traiter les entrées et les sorties d’une façon innovante, non-bloquante et asynchrone — ce qui est la caractéristique principale de Node.
Alors que le moteur V8 est dédié à l’interprétation du JavaScript, l’API fournie par la librairie libuv permet aux développeurs Node d’accéder à l’event loop. Cette dernière est par ailleurs distincte de la boucle d’événement interne aux navigateurs (JavaScript event loop) et qui leur permet d’exécuter le JS.
Qu’est-ce que l’event loop Node.js ?
Lorsque l’on exécute un programme sur son ordinateur, on crée une instance liée à ce programme. À celle-ci peut être attachée un ou plusieurs threads (ou fil d’exécution), qui correspondent à une suite d’opérations à faire réaliser par le processeur (CPU). La gestion et l’optimisation des threads est gérée par le système d’exploitation, qui leur alloue les ressources disponibles au bon moment.
Lorsque l’on exécute un programme Node.js, un seul thread est créé. C’est dans celui-ci que l’ensemble du code sera traité. À l’intérieur de ce fil d’exécution est générée la boucle d’événement ou event loop qui va décider quelle opération doit être exécutée et à quel moment. Pour cela, l’event loop communique avec le noyau (ou kernel) du système d’exploitation. Les noyaux modernes étant multi-threaded, ils peuvent exécuter plusieurs opérations en arrière-plan. Quand l’une d’elles est terminée, le kernel renvoie à Node.js le callbackcorrespondant (la fonction à exécuter à la suite de l’opération) pour être exécutée plus tard dans la boucle.
L’event loop accessible via libuv permet ainsi de lire chaque ligne de code, de l’interpréter, et d’en créer un événement à faire exécuter par le thread. Chaque événement est ainsi stocké dans une file d’attente appelée Event queue. En Node, il existe en réalité plusieurs types d’event queues qui correspondent à différents types d’événements. Ces différentes files d’attente sont traitées à des moments distincts, en plusieurs étapes successives qui constituent les phases de l’event loop.
Les différentes phases de l’event loop Node
Quand on lance une application Node, l’event loop est initialisée avant que le code soit interprété. Après l’interprétation, l’event loop est démarrée. Chaque itération (appelée tick) de la boucle passe par différentes phases, mais un tick ne peut démarrer que si des opérations sont en attente dans une event queue.
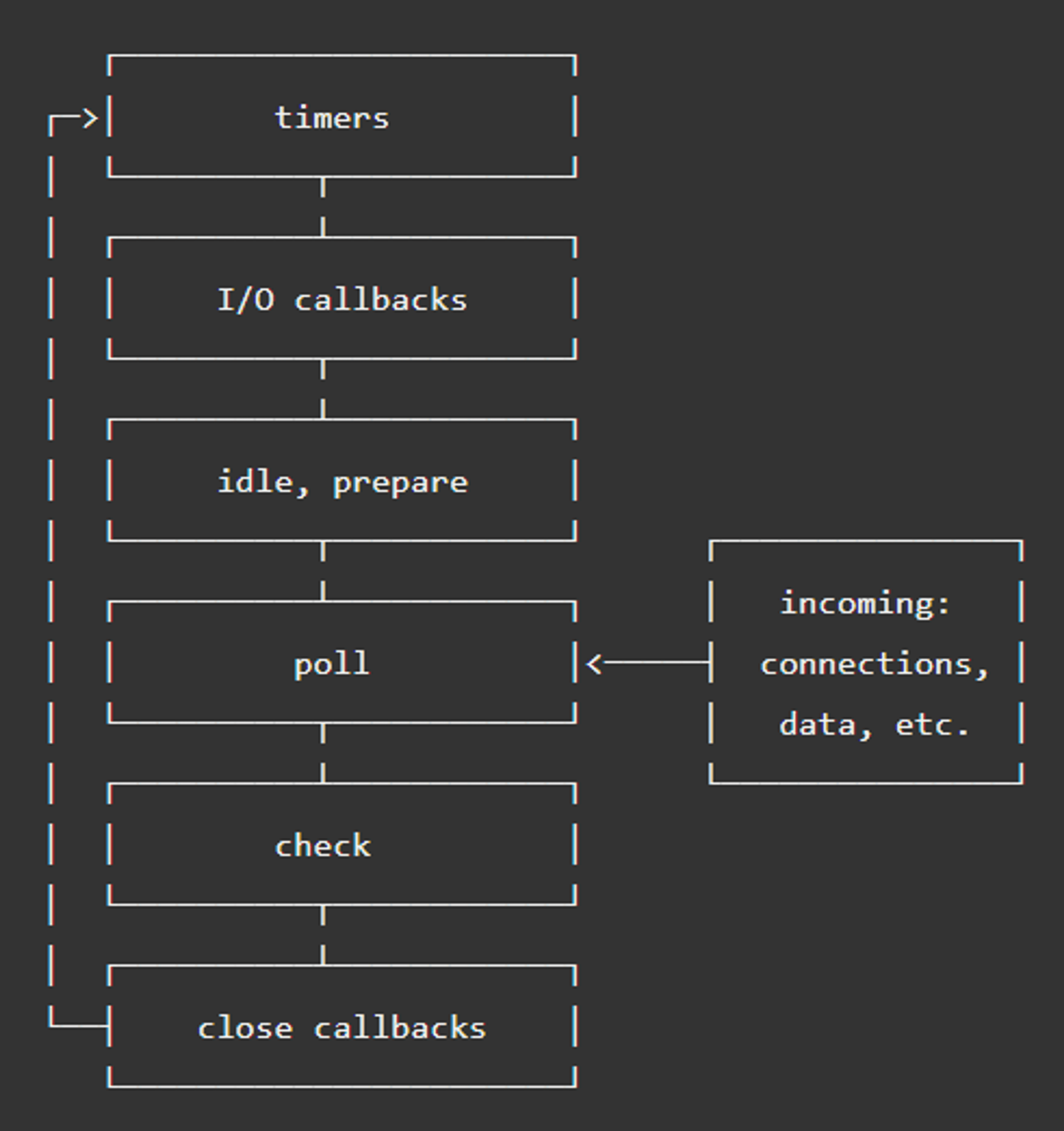
Illustration de l’event loop NodeJS
Une fois une itération commencée et qu’on rentre donc à l’intérieur d’un tick, l’event loop passe successivement par les étapes suivantes.
Phase 1 : les timers
Un timer spécifie un délai après lequel un callback sera exécuté. Ce délai peut être allongé, par exemple si des tâches réalisées par le système d’exploitation ou l’exécution d’autres callbacks empêchent l’exécution du callback du timer à temps. Lorsque le délai du timer est dépassé, le callback de celui-ci est placé dans une event queue, signifiant à Node qu’il est prêt à être exécuté.
Lorsqu’une itération de l’event loop est lancée, elle débute par cette première phase dans laquelle Node va exécuter les callbacks de timers prêts à être exécutés et placés en attente suite à l’expiration d’un setTimeout() ou d’un setInterval() — deux fonctions pour spécifier un délai en JavaScript.
Si chaque tick de l’event loop commence par cette phase, c’est pour s’assurer qu’un callback de timer soit exécuté le plus rapidement possible après sa mise en attente.
Quand tous ces callbacks de timers en attente sont exécutés (ou s’il n’y en a pas à exécuter), l’event loop passe à sa deuxième phase.
Phase 2 : les callbacks en attente
De la même façon que pour la première phase, Node va venir maintenant chercher des callbacks en attente dans une event queue pour les exécuter.
Cette fois, elle va chercher dans la file d’attente réservée aux callbacks d’opérations système comme les fonctions Node filesystem ou les erreurs TCP par exemple.
La boucle d’événement passe ensuite à la phase suivante, toujours à l’intérieur du même tick.
Phase 3 : l’interrogation ou poll phase
La troisième étape de l’event loop Node est la poll phase ou phase d’interrogation.Cette phase est plus complexe : durant celle-ci, Node va bloquer l’event loop et attendre de nouveaux événements pour les exécuter. Pour cela, Node va d’abord calculer la durée du blocage puis traiter les événements présents dans la poll queue (tous ceux non attribués dans les autres files d’attente).
Si la boucle d’événement entre dans la poll phase alors qu’aucun timer n’est planifié, deux possibilités existent :
- Si la poll queue n’est pas vide, la boucle va itérer sur les callbacks qui y sont présents et les exécuter l’un après l’autre jusqu’à ce qu’il n’y en ait plus ou que la limite du système soit atteinte.
- Si la poll queue est vide et qu’aucun script n’ait été planifié par `setImmediate()`, l’event loop est bloquée et continue à attendre de nouveaux callbacks à exécuter. Si des scripts ont été planifiés par `setImmediate()`, la boucle continue à l’étape suivante. Si des timers arrivent à expiration, la boucle revient à l’étape 1 pour les traiter.
Phase 4 : la vérification ou check phase
Quand on veut exécuter un script de façon asynchrone mais le plus rapidement possible, une option possible en Node est d’utiliser la fonction setImmediate(). N’importe quelle fonction passée en argument de setImmediate() est un callback à exécuter dans la prochaine itération de l’event loop.
C’est dans cette quatrième étape, la phase de vérification ou check phase que Node vient exécuter les événements de cette event queue. Ainsi, si la boucle est bloquée à la phase 3 et que des scripts ont été planifiés avec `setImmediate()`, l’event loop poursuit jusqu’à la phase 4 plutôt qu’elle ne continue d’attendre.
Phase 5 : les close callbacks
Lorsqu’un événement de type ‘close’ est émis, par exemple lorsqu’un socket est fermé avec socket.destroy(), il est placé dans l’event queue dédiée à cette étape. Lorsque la boucle atteint cette dernière phase, Node vient chercher les événements dans cette file d’attente et les émettre. Cette étape permet de “nettoyer” l’état de notre application avant de débuter une nouvelle itération de l’event loop.
Phases intermédiaires : nextTick et microtâches
Au-delà de ces cinq phases de l’event loop Node.js, qui correspondent donc à cinq event queues différentes, s’ajoutent deux files d’attente supplémentaires qui ne font pas partie de libuv mais qui sont implémentées par Node. On peut les qualifier de phases intermédiaires :
- process.nextTick() : les scripts appelés par cette fonction ne sont pas traités par l’event loop à proprement parler, comme peuvent l’être ceux de
setImmediate()ousetInterval()par exemple. Au contraire, un script appelé parprocess.nextTick()est stocké dans la nextTickQueue. Les événements présents dans cette file d’attente sont systématiquement traités juste après l’opération en cours, peu importe la phase à laquelle se trouve l’event loop. Qu’importe le moment oùprocess.nextTick()est appelé, l’event loop est bloquée le temps de l’exécuter, ce qui peut causer des comportements inattendus telle que l’impossibilité pour la boucle d’atteindre la poll phase. - microtâches : les microtâches ou microtasks sont les callbacks de promises résolues (.then/catch/finally). Elles rejoignent une queue spécifique qui est elle aussi exécutée entre deux phases, mais toujours après que la nextTickQueue fut vidée.
Bonnes pratiques pour maîtriser l’event loop
En tant que l’un des trois fondements de Node.js, la connaissance et la maîtrise de l’event loop et des contraintes qui lui sont associées sont indispensables pour réussir une application Node. Une mauvaise utilisation de certaines fonctions peut complètement bloquer l’event loop et causer de nombreux bugs très difficiles à repérer et à résoudre.
Eviter de répéter fréquemment les fonctions I/O synchrones
En Node, on définit généralement toutes les fonctions faisant appel au système ou au réseau comme étant des fonctions I/O (pour input/output). Toutes les fonctions I/O standards de Node.js sont asynchrones : elles ne bloquent pas l’event loop et acceptent des callbacks qui sont exécutés dans les conditions vues précédemment. Certaines existent également en version synchrone, c’est-à-dire qu’elles bloquent l’event loop pendant leur exécution, l’empêchant de poursuivre vers d’autres phases et d’exécuter le reste du code.
Pour ne pas bloquer l’event loop, il ne faut pas utiliser les fonction I/O synchrones (telles que fs.readFileSync() ou fs.renameFileSync() par exemple) dans des blocs de code appelés à répétition telles que des boucles ou des fonctions fréquemment répétées.
La meilleure pratique est bien souvent de réaliser ces opérations pendant l’initialisation de l’app.
Uniquement écrire des fonctions 100% synchrones ou 100% asynchrones
Une règle d’or en Node est de n’écrire que des fonctions uniquement synchrones ou uniquement asynchrones.
- Entièrement synchrone et donc bloquante : on utilisera alors uniquement des fonctions synchrones telles que, par exemple, celles qui retournent leur résultat avec return (fonctions Math, fonctions standards se terminant par Sync etc.) ou celles qui traitent des prototypes d’array (map, filter, reduce etc.)
- Entièrement asynchrone et donc non bloquante : on ne choisira ici que des fonctions asynchrones qui retournent leur résultat avec un callback ou une promise
Si votre fonction est un hybride entre synchrone et asynchrone, elle aura des résultats irréguliers et imprévisibles. Il faut donc, pour chaque fonction que l’on crée, choisir un caractère bloquant ou non-bloquant et s’y tenir.
Ne pas abuser des nextTicks !
process.nextTick() peut être très utile pour s’assurer qu’un script soit immédiatement exécuté. Il est cependant à utiliser avec parcimonie car son utilisation trop fréquente peut forcer l’event loop à se concentrer exclusivement sur le traitement de la nextTickQueue et la bloquer entre deux phases. Si la poll phase n’est jamais atteinte par l’event loop, le reste du code n’est pas exécuté et l’app est bloquée.
Ajuster la taille du thread pool
Pour les opérations I/O coûteuses en ressources, libuv maintient un thread pool qui contient plusieurs threads prêts à être utilisés en même temps. La taille de ce thread pool est limitée, par défaut à 4 threads. Cela signifie par exemple qu’au maximum 4 opérations de lecture d’un fichier sur le disque peuvent être réalisées en même temps. Les autres seront délayées le temps que les premières soient terminées et que leurs threads soient à nouveau disponibles.
Cette limite peut être augmentée en ajustant la variable d’environnement UV_THREADPOOL_SIZE qui peut être augmentée jusqu’à 128. Ce sont alors théoriquement autant d’opérations I/O qui pourront être réalisées en même temps, augmentant drastiquement les performances de l’application par rapport à la valeur par défaut, dans certains cas. Les performances sont en effet toujours relatives aux limites du système sur lequel l’application est hébergée.
Monitorer l’event loop
Surveiller l’état de la boucle d’événement est indispensable pour empêcher des dysfonctionnements et peut être utilisé pour créer des alertes, forcer un redémarrage ou aider à scaler l’app.
Le but du monitoring de l’event loop est d’identifier des délais supplémentaires dans l’exécution d’un callback de timer. Si un timer met plus de temps que ce qu’on lui a spécifié pour s’exécuter, c’est que la boucle d’événement a été délayée. Ce délai représente le temps nécessaire pour que l’event loop exécute les autres phases. On pourrait dès lors par exemple imposer un seuil limite à partir duquel notre application serait considérée comme surchargée et appliquer automatiquement les mesures nécessaires.



