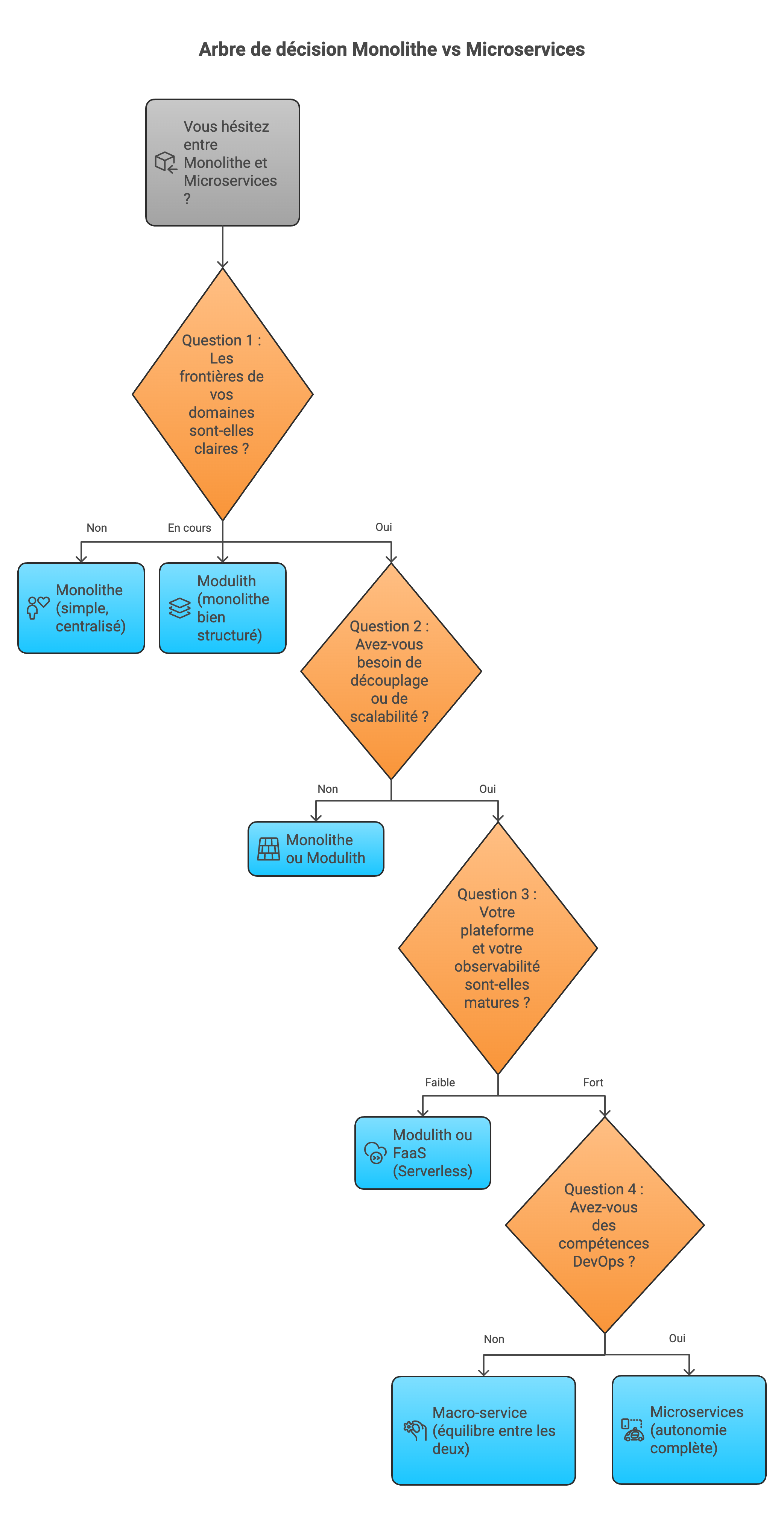
En 2025, le débat monolithe vs microservices n’est toujours pas tranché. Faut-il garder une architecture monolithique ou découper en microservices ? Et surtout, dans quels cas choisir l’un ou l’autre ?
Sur LinkedIn, Julien Bideau, Engineering Manager chez Doctolib, raconte leur sortie de la boring architecture. En neuf mois, ils ont réduit leur CI de 1 h à 5 minutes, un changement qui transforme le quotidien des équipes.
Doctolib n’est pas un cas isolé. Twitter avait déjà cassé son monolithe Rails plusieurs années auparavant. Et j’ai interviewé de nombreux développeurs et CTO qui ont vécu ce mouvement : « On sort des fonctionnalités du monolithe Rails et on fait des microservices avec Node. »
L’inverse existe aussi. Amazon Prime Video est souvent l’exemple cité. En pratique ils sont passé de Serverless à Monolithe et je vous expliquerai aussi la différence dans cet article.
J’ai également posé des questions à Vincent Vauban, pour comprendre ce qui a changé cette année et avoir l’argumentaire le plus au point. Sa lecture est éclairante : la durabilité et la clarté comptent désormais plus que l’élasticité théorique.
Que vous soyez leader tech, manager ou développeur, cet article vous propose une méthode pour choisir la bonne architecture selon votre projet : comprendre les bonnes raisons de rester en monolithe, celles de passer aux microservices, et surtout, éviter les erreurs classiques qui transforment un projet en casse-tête.
Ces questions sont le point de départ avant toute migration de monolithe vers des microservices.
Oui parce que personne ne naît micro-service. On le devient.
Même si vous n’êtes pas encore adepte du DDD (Domain Driven Design), vous comprenez ce qu’est un domaine.
Chez Doctolib, la réservation de rendez-vous en est un. La gestion du dossier patient en est un autre. La téléconsultation aussi.
Quand le métier n’est pas encore mature, que l’application n’a pas assez d’heures de vol, on ne sait pas toujours où placer ces frontières.
Et les placer trop tôt peut coûter plus cher qu’autre chose.
Imaginez que votre applicatif soit une cuisine d’entreprise.
Demain, vous voudrez peut-être douze micro-ondes, comme chez Swile : c’est la scalabilité horizontale.
Ou au contraire, enlever les fours parce que personne ne fait de gâteaux : c’est le scale-to-zero.
Ou encore changer le lave-verre pour un lave-vaisselle géant : c’est la scalabilité verticale.
Toutes ces situations traduisent une même question :
votre architecture doit-elle monter en charge, réduire à zéro, ou simplement grossir différemment ?
Aller vers les microservices sans plate-forme solide, c’est sauter en parachute sans vérifier le matériel.
Julien Bideau précise que Doctolib a mis plusieurs mois à monter en compétence sur Terraform et Kubernetes. Ce n’est pas anodin.
Et si vous passez votre réveillon avec un beau-frère qui bosse chez Datadog, il vous rappellera sans doute que l’observabilité est un métier à part entière.
Ce que j’aime dans la prise de parole de Doctolib, c’est qu’il parle de capacités, pas seulement de domaines.
Cela vient du vocabulaire DORA (DevOps Research & Assessment) : une approche qui mesure la maturité DevOps avec quatre indicateurs simples :
Si vous ne pouvez pas suivre ces quatre indicateurs, votre plate-forme n’est pas prête pour la complexité d’une architecture distribuée.
Les adeptes du microservice vous expliquent souvent qu’ils gagnent en autonomie.
Julien Bideau clashe gentiment cet a priori.
Quand ta mise en prod reste coincée dans les tuyaux et que tu as besoin d’un SRE qui n’est pas dispo parce qu’il aide une autre équipe…
Bah tu n’es pas si autonome que ça.
Donc oui : avant de sauter en parachute, vérifie qu’il y a quelqu’un pour piloter l’avion.
Et pour la taille ? Pensez à la loi de Conway.
“Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.”
(Melvin Conway, 1967)
12 personnes c’est le maximum pour qu’une équipe reste efficace. Si vous êtes 15, coupez en deux ou trois. Dans l’absolu si votre équipe Dev/Ops ne va jamais dépasser 10 personnes, vous n’avez sûrement pas besoin de microservices dès aujourd’hui. Doctolib a attendu d’être à plusieurs centaines d’ingénieurs pour changer.
Quand un projet a besoin de stabilité, le monolithe reste souvent la bonne solution.
Chaque version, chaque release est maîtrisée. Vous pouvez tester tout, de fond en comble, avant la mise en production.
Oui, c’est de la boring architecture, comme le disent ses détracteurs.
Mais c’est aussi pratique de pouvoir refactorer tout le code en une fois, sans avoir à jongler entre dix dépôts Git et autant de pipelines CI/CD.
Le revers de la médaille ?
Une CI qui s’allonge au fil du temps.
Des commits qui attendent la prochaine version pour voir la prod, parfois plusieurs semaines.
Les merge deviennent complexes, et on finit par inventer des anti-patterns pour les éviter.
Vous avez déjà vu cinq développeurs se prévenir sur Slack avant de modifier un fichier ?
Moi oui.
On a déjà dédié un article complet au sujet : Architecture modulith : tout comprendre.
On pourrait résumer ainsi :
Un modulith, c’est un monolithe bien codé.
Il applique les principes du DDD (Domain Driven Design) pour créer des modules parfaitement délimités.
Chaque module correspond à un domaine métier clair : on sait ce qui rentre, ce qui sort, et où s’arrête sa responsabilité.
L’objectif ?
Pouvoir extraire ce module plus tard, sans tout réécrire, s’il doit devenir un microservice.
Avec un peu de configuration Gradle, il est même possible de bypasser un module qui ne serait pas utile au runtime.
Ce n’est pas du scale automatique, mais c’est déjà un début d’équilibrage des charges par capacité.
Et s’il ne fallait retenir qu’une seule règle du modulith :
on n’accède pas directement aux données d’un module, on les demande au module.
C’est la base de l’isolation.
Le problème des microservices, c’est toujours la granularité.
Les macro-services, parfois appelés “migroservices”, adoptent une approche plus raisonnée :
on ne décompose pas tout, et surtout pas jusqu’au plus petit service possible.
J’ai déjà vu des architectures où, sur une même route, un microservice différent répondait selon le verbe HTTP.C’est le genre d’excès qu’on cherche justement à éviter.
L’idée, c’est de rester au niveau d’une capacité (ex. Prendre un rendez-vous) ou d’un domaine métier (ex. Dossier patient). Ce niveau de découpe permet de réduire les coûts de déploiement et la complexité d’orchestration.
Côté organisation, c’est aussi plus naturel :
un macro-service = une équipe.
Une équipe peut en gérer plusieurs, mais pas dix.
Le principal écueil reste la dépendance cyclique. Prenons un cas concret : la capacité Prise de rendez-vous doit appeler le service Dossier patient. Sauf que Dossier patient contient lui-même des informations de rendez-vous.
Résultat : si vous déployez Dossier patient sans Prise de rendez-vous, vous risquez un incident en production. Il faut alors déployer les deux ensemble, ou introduire un composant de découplage (événement, file, orchestrateur…).
Mais tout cela, normalement, un module bien conçu l’a déjà réglé.
Un microservice, c’est pratique : on peut le déployer facilement et à tout moment. Le premier bénéfice attendu, c’est un lead time excellent. Doctolib mentionne une CI passée d’une heure à cinq minutes, un bond spectaculaire. Tous les KPIs DevOps en profitent : on déploie plus souvent, on corrige plus vite, on réduit le Change Failure Rate et le MTTR. Quand une vulnérabilité apparaît, elle peut être patchée sans attendre la prochaine version globale.
Le code est bien isolé. Pas besoin de comprendre toute la base pour intervenir. Cet isolement profite aussi à l’IA : les assistants de code ne sont plus perdus dans un monstre de 200 000 lignes.
Autre avantage : la finesse de pilotage des ressources. Chaque service peut être dimensionné selon sa charge.
Chez Twitter, par exemple, le service “Créer un tweet” a ses propres ressources et peut monter en puissance en temps réel, notamment pendant le Super Bowl.
Et surtout, les développeurs se sentent propriétaires. C’est leur service, leur pipeline, leur runbook. Ils sont responsables du ticket JIRA jusqu’à la production. Cet ownership, c’est la promesse tenue du modèle microservices. Mais cette liberté a un prix : chaque service demande sa CI/CD, son observabilité, ses SLOs. Plus de puissance, oui, mais aussi plus d’entretien.
Les microservices sont séduisants sur le papier. En pratique, ils peuvent vite tourner à la jungle. Dans certaines équipes, on voit même apparaître des microservices qui servent… à compenser d’autres microservices. Par exemple, un service souffre de lenteurs ? On rajoute devant lui un microservice proxy qui met en cache sa réponse. Pratique, non ? Jusqu’au jour où le proxy tombe et où tout le reste s’écroule avec lui.
La latence cross-service devient vite un sujet. Imaginons un service qui sollicite deux autres services pour répondre à une requête. À 18 h, en pleine charge, son temps de réponse dépasse la seconde. On double le nombre d’instances ? Rien ne change. En observant les services en amont, on découvre qu’ils sont eux aussi lents sur le même créneau : tous les deux appellent un troisième service sous-dimensionné.
C’est le piège classique : une chaîne de dépendances invisibles qui se met à tirer sur le fil. L’orchestration devient un casse-tête, et sans observabilité solide, vous ne savez plus où passe le temps. J’ai déjà vu des développeurs backend Spring qui n’avaient plus écrit une seule requête SQL depuis dix ans, simplement parce que leurs services ne savaient plus où était la donnée à la fin du pipeline.
Au début, tout le monde est content de pouvoir déployer chaque service indépendamment. Mais au fil du temps, on doit prévenir cinq, dix voisins à chaque changement, maintenir des vieilles routes pour ne pas casser les dépendances, ou versionner chaque endpoint comme une API publique. Et là, on réalise que l’autonomie promise ressemble étrangement à de la coordination permanente.
Le monitoring d’un monolithe, c’est souvent simple : une base de logs quelque part, un APM comme New Relic, et tout le monde dort tranquille. Mais quand vous essayez de déboguer une forêt de microservices, la donne change. Pour comprendre ce qui se passe, il faut beaucoup de logs — et surtout la capacité de les recouper entre plusieurs sources.
Chaque service finit par écrire sa petite trace : “Je passe la balle à mon voisin.” Il faut du timestamp précis, sinon les messages ne seront pas dans l’ordre une fois regroupés. Et très vite, vous vous retrouvez avec une base de données timeseries plus complexe que celle du métier.
C’est pour ça que Splunk et Datadog coûtent une fortune : leur infrastructure est parfois plus sophistiquée que celle de votre propre application.
Le Serverless est un modèle d’exécution où le code ne tourne que lorsqu’il est appelé.
La plupart du temps, il repose sur le FaaS (Function as a Service) : des fonctions indépendantes, déclenchées par des événements.
En clair, le FaaS est la forme la plus courante du Serverless, mais il ne s’agit pas d’une architecture microservices.
C’est ce qu’a expérimenté Amazon Prime Video.
Une partie de son système de traitement vidéo fonctionnait sur un enchaînement de fonctions AWS Lambda : à chaque lecture, la plateforme devait convertir ou analyser le flux pour l’utilisateur, via un pipeline Serverless orchestré par Step Functions.
Le problème, c’est le cold start.
Quand la première requête arrive, les fonctions doivent démarrer à froid et la réponse peut prendre plusieurs secondes.
Autrement dit, quand vous cliquez sur “Lecture” sur Prime Video, vous ne voulez pas attendre que le back-end se réveille.
Ce modèle, idéal pour les traitements asynchrones (conversion, analyse, post-traitement), devient intenable pour les usages en temps réel.
Le curseur est simple : si une fonctionnalité doit répondre immédiatement, en continu et sans latence, il faut la placer sur un microservice.
Si vous cherchez plutôt l’élasticité, la facturation à l’usage et un scale-to-zero natif, les fonctions Serverless sont la bonne solution.
Mais les fonctions ne sont pas sans limites. Leur gouvernance devient complexe, le déploiement difficile à automatiser et le débogage local souvent bancal.
C’est d’ailleurs pour ces raisons qu’Amazon Prime Video a fini par regrouper plusieurs fonctions Serverless dans un service monolithique : moins d’appels distribués, plus de performances et une facture réduite de près de 90 % sur leur pipeline de monitoring vidéo.
Les microservices demandent un outillage adapté et une réelle maturité d’équipe.
Les quatre questions de l’introduction servent déjà de guide de gouvernance logicielle.
Si vous n’avez pas encore les réponses, ou si vous ne suivez pas les indicateurs DORA (DevOps Research and Assessment), il y a de fortes chances que votre projet se passe mieux avec un monolithe.
Ne vous interdisez pas pour autant d’utiliser des Lambdas, Functions ou autres services Serverless dès le début, pour vos traitements asynchrones et vos batchs.
Ces briques fonctionnent très bien de manière isolée : leur échec n’a pas d’impact sur le reste de l’architecture.
Évitez simplement de les empiler ou de créer des déclenchements cycliques difficiles à tracer.
Et dès que vous aurez la charge et la maturité d’un acteur comme Amazon Prime Video, vous pourrez envisager de refondre certaines parties de votre application sous forme de microservices.
Mais souvenez-vous : le bon choix n’est pas celui qui fait le plus moderne, c’est celui qui vous permet de livrer plus vite, de corriger plus sereinement et de dormir tranquille.
Le marché de la tech en 2026 est en pleine mutation. Entre la démocratisation massive…
Comment optimiser tes coûts data dans le cloud ? Face à des factures cloud qui…
Changer de stack ça fait peur parce qu'on ne sait pas comment s’y prendre. Ça…
Ah, le télétravail... Travailler en slip (ou en pyjama licorne, on ne juge pas) avec…
On aurait pu penser que la tendance DevOps n’était qu’une transition, portée par le Move2Cloud…
Une question simple "Où sont les développeuses ?" , une réponse complexe. C’est la question…
{kind=link}